2025火山引擎原动力大会:英特尔揭示AI下半场真相
2025-12-19
21:07:33
来源: 杜芹
点击
在AI大模型进入“应用为王”的2025年,行业对算力的追求正经历一场深刻的范式转移:单纯的算力堆砌已无法满足业务爆发式增长的需求,如何将底层架构、数据流转、机密计算与具体业务场景深度耦合,构建“全景系统化加速方案”,成为了科技巨头角逐的新战场。
12月18日,在上海举行的2025火山引擎FORCE原动力大会·冬,英特尔与火山引擎交出了一份重量级答卷。从基础设施的底层重构到“数字员工”的丝滑落地,双方不仅展示了全栈合作成果,更揭示了一个核心趋势:AI正从单点能力的演进,迈向全面系统化的业务支撑。

英特尔与火山引擎携手做了哪些事?
英特尔与火山引擎做的第一件事,是向基础设施的“隐性成本”宣战。火山引擎开源的存储加速优化库 veSAL,以及它与英特尔至强6处理器内置加速能力的结合方式。veSAL利用至强6上的QAT(数据保护与压缩加速技术)与DSA(数据流加速器),把压缩、解压、加解密、哈希、数据搬运、CRC等高频高负载任务做硬件卸载,从而显著释放CPU通用核的压力,提升数据处理效率。

这种“硬核”优化使得吞吐量达到了单核CPU的30-50倍。在第四代火山引擎ECS实例上,通用计算性能提升约20%,Redis性能提升30%。这意味着,企业在处理海量多媒体数据时,能够以更低的时延和更小的CPU消耗,换取更强的业务表现。
它真正击中的,是AI系统最容易被低估的一段:数据管道与基础设施的“隐性成本”。现实里,AI推理只是链路的一部分,更多资源消耗往往发生在数据进入推理之前与推理之后的处理、搬运与合规动作上;当把这些动作从通用核中剥离出来,吞吐、时延、资源占用都会发生质变,云厂商与企业用户看到的将不仅是“更快”,更是更可控的TCO。
第二个关键点,是双方把“视频AI链路”做成了可落地的、CPU可承担的全流程方案。基于英特尔® 至强® 6 性能核处理器与火山引擎g4i实例,双方围绕视频编解码、AI视频增强、并行调度进行了系统级优化,并通过AVX-512 VNNI、AMX以及英特尔® iVTAL智能媒体软件库形成软硬协同,让用户在云端通过镜像一键部署就能完成转码、增强、抽帧与智能分析等任务。
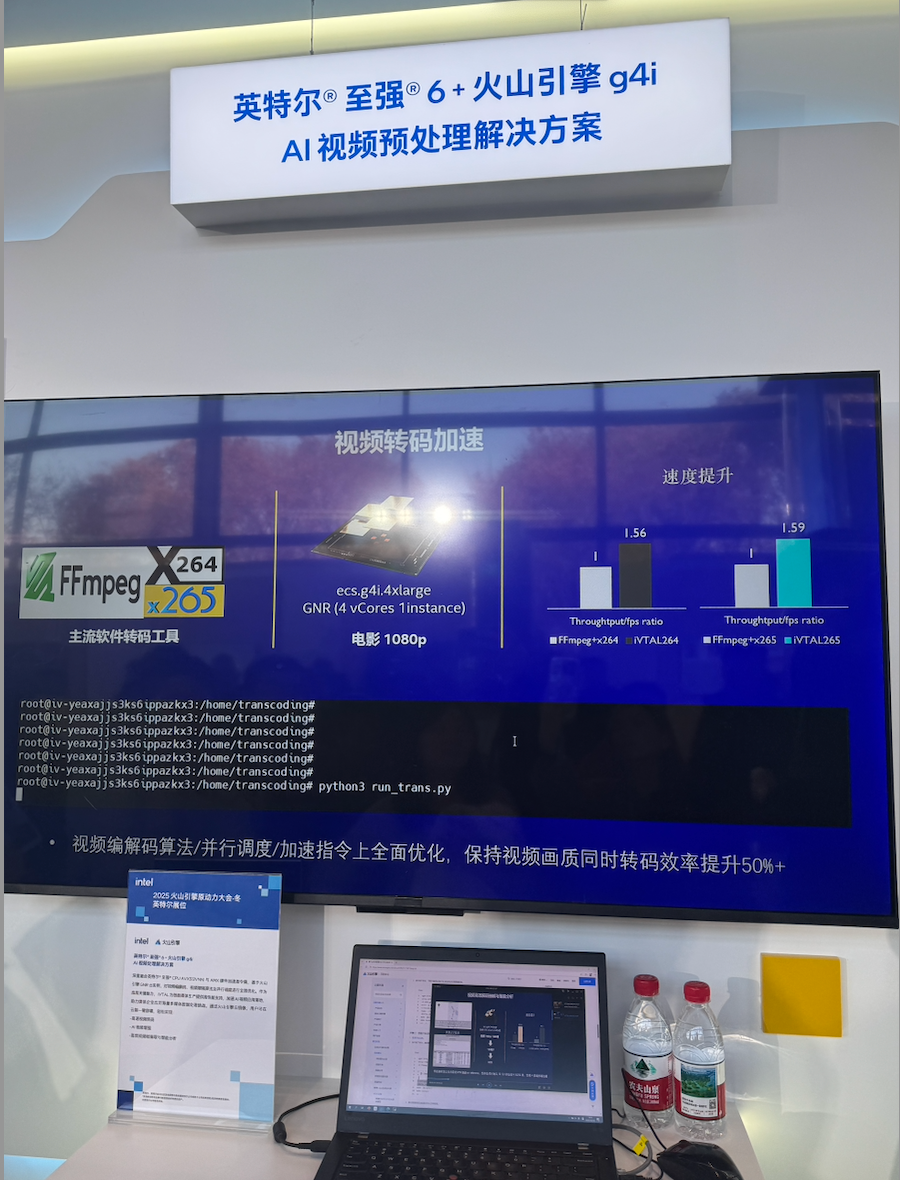
这背后的产业含义,是对“GPU从头跑到尾”路径的一种现实补充:不是所有视频AI都必须把每一环都压在GPU上,当CPU侧的指令集与媒体库把关键环节啃下来,云上的弹性与成本结构就会更健康,GPU资源也能更聚焦在真正不可替代的推理与渲染段。对于云平台而言,这类“链路型优化”的价值往往比某个点的极限性能更大,因为它直接影响部署复杂度、资源利用率与客户的交付速度——而这些才是视频类AI应用能否规模化的决定因素。
第三个更具前瞻性的信号,是双方对“智能体时代的可信底座”提前下注。火山引擎Jeddak AICC机密计算平台深度融合英特尔® TDX技术,并开源Trusted MCP方案,试图解决原生MCP协议中的安全威胁,为智能体间通信提供全链路加密与可信状态验证,同时提供远程证明、端云互信、机密容器等能力,并进一步支持硬件隔离的GPU机密计算。在Agent逐渐成为企业应用主形态的趋势下,这一步并不是锦上添花,而更像基础设施的“先修课”:当智能体数量变多、链路变长、工具调用频繁,数据与模型资产的暴露面会急剧扩大,安全如果只停留在应用层策略,很容易被复杂协同场景击穿;反过来,一旦可信执行环境成为默认能力,企业在合规与风控上的心理门槛会被明显降低,智能体协作才有机会真正走向规模化与产品化。

场景落地,方为根本
如果把上述基础设施能力看作“底盘”,那么英特尔在展位上展示的几个场景方案,则更像是把底盘包装成行业能直接拿走的“整车”。
在内容创作场景,AI PC端云混合AI视频剪辑方案,用“端侧解析—云端规划—本地执行”的流程把VLM与LLM分工明确化:端侧GPU负责对素材进行深度解析并结构化,云端LLM依据用户指令完成主题挖掘、故事线规划、分镜编排、字幕与配乐生成,最后任务回到本地完成剪辑合成与导出。这种端云协同范式,表面上是降低剪辑门槛、提升效率,实质上是在探索生产力应用的新架构:让端侧贴近数据与交互,让云端承担重规划与智能决策,让本地负责可控的最终交付,从而在体验、隐私与成本之间找到可复制的平衡点。
在办公领域,双方携手华胜天成、联想推出的社区全能数字员工“华格格”。该方案搭载英特尔锐炫™ B60显卡与火山引擎HiAgent框架。其亮点在于“画布式交互”,打破了传统对话框的局限。依托本地ThinkStation工作站的强大算力,实现了多智能体跨域调度,将“算力成本”与“部署效率”做到了平衡。

在沉浸式体验场景,英特尔联合PICO与懂车帝推出VR汽车导览方案,依托处理器与显卡算力结合RTC技术,实现多路高清视频流的低延迟传输,让用户即便身处异地,也能通过6DoF技术获得如临其境的虚拟试车体验。

结语
把这些点串起来,会发现英特尔这次更像是在做一件事:把CPU/加速单元/可信计算等硬件能力,变成云原生可调用的系统能力,再通过场景方案把能力变成交付。它对产业格局的含义是:
1)AI基础设施的竞争,正在从“卖硬件”走向“卖体系”。谁能把数据链路、推理优化、机密计算、资源弹性、工具链打通,谁就更接近“企业级默认选项”。
2)CPU在AI时代不会消失,而是“角色更清晰”。训练/核心推理之外,还有大量链路环节更适合CPU+专用加速。把这些做成体系,CPU就不再只是“配角”。
3)开源是进入云栈的最快方式之一。veSAL、Trusted MCP的开源姿态,既是生态入口,也是“让客户敢用”的信任机制。
从这次大会展示来看,英特尔与火山引擎把重心放在了两个关键词上:全局效率优化与动态智能协同。这是一种更接近“产业真实”的AI叙事:不再迷恋某个单点爆发,而是追求可复制、可规模、可持续的落地。
12月18日,在上海举行的2025火山引擎FORCE原动力大会·冬,英特尔与火山引擎交出了一份重量级答卷。从基础设施的底层重构到“数字员工”的丝滑落地,双方不仅展示了全栈合作成果,更揭示了一个核心趋势:AI正从单点能力的演进,迈向全面系统化的业务支撑。
英特尔与火山引擎携手做了哪些事?
英特尔与火山引擎做的第一件事,是向基础设施的“隐性成本”宣战。火山引擎开源的存储加速优化库 veSAL,以及它与英特尔至强6处理器内置加速能力的结合方式。veSAL利用至强6上的QAT(数据保护与压缩加速技术)与DSA(数据流加速器),把压缩、解压、加解密、哈希、数据搬运、CRC等高频高负载任务做硬件卸载,从而显著释放CPU通用核的压力,提升数据处理效率。
这种“硬核”优化使得吞吐量达到了单核CPU的30-50倍。在第四代火山引擎ECS实例上,通用计算性能提升约20%,Redis性能提升30%。这意味着,企业在处理海量多媒体数据时,能够以更低的时延和更小的CPU消耗,换取更强的业务表现。
它真正击中的,是AI系统最容易被低估的一段:数据管道与基础设施的“隐性成本”。现实里,AI推理只是链路的一部分,更多资源消耗往往发生在数据进入推理之前与推理之后的处理、搬运与合规动作上;当把这些动作从通用核中剥离出来,吞吐、时延、资源占用都会发生质变,云厂商与企业用户看到的将不仅是“更快”,更是更可控的TCO。
第二个关键点,是双方把“视频AI链路”做成了可落地的、CPU可承担的全流程方案。基于英特尔® 至强® 6 性能核处理器与火山引擎g4i实例,双方围绕视频编解码、AI视频增强、并行调度进行了系统级优化,并通过AVX-512 VNNI、AMX以及英特尔® iVTAL智能媒体软件库形成软硬协同,让用户在云端通过镜像一键部署就能完成转码、增强、抽帧与智能分析等任务。
这背后的产业含义,是对“GPU从头跑到尾”路径的一种现实补充:不是所有视频AI都必须把每一环都压在GPU上,当CPU侧的指令集与媒体库把关键环节啃下来,云上的弹性与成本结构就会更健康,GPU资源也能更聚焦在真正不可替代的推理与渲染段。对于云平台而言,这类“链路型优化”的价值往往比某个点的极限性能更大,因为它直接影响部署复杂度、资源利用率与客户的交付速度——而这些才是视频类AI应用能否规模化的决定因素。
第三个更具前瞻性的信号,是双方对“智能体时代的可信底座”提前下注。火山引擎Jeddak AICC机密计算平台深度融合英特尔® TDX技术,并开源Trusted MCP方案,试图解决原生MCP协议中的安全威胁,为智能体间通信提供全链路加密与可信状态验证,同时提供远程证明、端云互信、机密容器等能力,并进一步支持硬件隔离的GPU机密计算。在Agent逐渐成为企业应用主形态的趋势下,这一步并不是锦上添花,而更像基础设施的“先修课”:当智能体数量变多、链路变长、工具调用频繁,数据与模型资产的暴露面会急剧扩大,安全如果只停留在应用层策略,很容易被复杂协同场景击穿;反过来,一旦可信执行环境成为默认能力,企业在合规与风控上的心理门槛会被明显降低,智能体协作才有机会真正走向规模化与产品化。
场景落地,方为根本
如果把上述基础设施能力看作“底盘”,那么英特尔在展位上展示的几个场景方案,则更像是把底盘包装成行业能直接拿走的“整车”。
在内容创作场景,AI PC端云混合AI视频剪辑方案,用“端侧解析—云端规划—本地执行”的流程把VLM与LLM分工明确化:端侧GPU负责对素材进行深度解析并结构化,云端LLM依据用户指令完成主题挖掘、故事线规划、分镜编排、字幕与配乐生成,最后任务回到本地完成剪辑合成与导出。这种端云协同范式,表面上是降低剪辑门槛、提升效率,实质上是在探索生产力应用的新架构:让端侧贴近数据与交互,让云端承担重规划与智能决策,让本地负责可控的最终交付,从而在体验、隐私与成本之间找到可复制的平衡点。
在办公领域,双方携手华胜天成、联想推出的社区全能数字员工“华格格”。该方案搭载英特尔锐炫™ B60显卡与火山引擎HiAgent框架。其亮点在于“画布式交互”,打破了传统对话框的局限。依托本地ThinkStation工作站的强大算力,实现了多智能体跨域调度,将“算力成本”与“部署效率”做到了平衡。
在沉浸式体验场景,英特尔联合PICO与懂车帝推出VR汽车导览方案,依托处理器与显卡算力结合RTC技术,实现多路高清视频流的低延迟传输,让用户即便身处异地,也能通过6DoF技术获得如临其境的虚拟试车体验。
结语
把这些点串起来,会发现英特尔这次更像是在做一件事:把CPU/加速单元/可信计算等硬件能力,变成云原生可调用的系统能力,再通过场景方案把能力变成交付。它对产业格局的含义是:
1)AI基础设施的竞争,正在从“卖硬件”走向“卖体系”。谁能把数据链路、推理优化、机密计算、资源弹性、工具链打通,谁就更接近“企业级默认选项”。
2)CPU在AI时代不会消失,而是“角色更清晰”。训练/核心推理之外,还有大量链路环节更适合CPU+专用加速。把这些做成体系,CPU就不再只是“配角”。
3)开源是进入云栈的最快方式之一。veSAL、Trusted MCP的开源姿态,既是生态入口,也是“让客户敢用”的信任机制。
从这次大会展示来看,英特尔与火山引擎把重心放在了两个关键词上:全局效率优化与动态智能协同。这是一种更接近“产业真实”的AI叙事:不再迷恋某个单点爆发,而是追求可复制、可规模、可持续的落地。
责任编辑:duqin
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号