量电融合,国产QPU+GPU 联手破局“后摩尔时代”
2025-12-26
12:47:34
来源: 杜芹
点击
过去十年,算力的主线始终围绕着工艺微缩、架构优化和加速器堆叠展开。但今天,三条现实约束正在同时收紧:先进制程推进的边际收益下降、数据中心能耗与散热成为系统级瓶颈、超大规模问题的计算复杂度,开始超出经典计算的可承受范围。在这一背景下,量子计算不再被视为“遥远的实验室技术”,而是被纳入算力长期演进路线的一部分。
在12月20日-21日的摩尔线程首届MUSA开发者大会上,摩尔线程与量子计算领域的领先企业图灵量子正式签署战略合作协议,在英伟达凭借NVQLink布局“量子-经典协同”方案的全球背景下,这一动作标志着中国版“量电融合”方案也正式开始试水。

图灵量子技术总监赵翔博士在MUSA开发者大会“AI4S”的技术论坛发表主题演讲
QPU 与 GPU,一场“双向奔赴”的互补
长期以来,公众对量子计算存在一种误解——认为它将全面取代经典计算。但事实恰恰相反。
“GPU是‘大数据、大计算’,擅长矩阵运算和大规模并行;而QPU是‘小数据、超大计算’,适合处理NP完全问题等极端复杂的搜索与模拟。”图灵量子技术总监赵翔博士在采访中这样概括两者的分工。
在 NP 类问题中,这种差异尤为明显:当问题规模进入指数爆炸区间,即便是万卡 GPU 集群,也只能在解空间边缘徘徊;而量子计算可以在物理层面同时探索大量状态,这是经典算法难以逼近的能力。
但这并不意味着QPU 可以“独立作战”。相反,当前量子计算真正的工程瓶颈,并不在于“算不算得快”,而在于如何在极短时间内完成纠错与控制。
“现在量子比特非常脆弱,大约每 1000 次操作就可能出一次错。”赵翔坦言,“量子计算不是不能出错,而是必须能及时纠错。”而纠错的关键约束,是时延:从微秒级,走向亚微秒级。
这正是 GPU 进入量子计算体系的根本原因。纠错、反馈、调度,本质上都是高并行、低时延的经典计算任务,GPU是量子计算走向可用性的一大支撑。在量子机器学习(QML)中,并不是所有逻辑都在量子端运行。一部分由GPU跑基础模型,一部分由QPU执行复杂的量子变换,这种混合架构能让计算效率达成数量级的跨越。
为了实现这种极致的响应,图灵量子推出了XLINK架构——纳秒级 CPU–GPU–QPU 任意互联架构。与早期依赖 FPGA 进行中转与控制的方案不同,XLINK基于 CPO(光电共封) 的光互连路径,通过光互连交换与分布式集群架构,将 CPU、GPU 与 QPU 纳入同一高速互联网络之中。

在“AI4S”的技术论坛上,赵博士在演讲中指出,当下,量子计算正在经历一场从“异构协作”走向“深度融合”的范式迁移。在其描绘的时间轴上,2019—2024 年是以量子模拟和专用量子计算为主的探索期,量子优势依赖经典超算进行验证,量子硬件以专用“外挂”形态存在;而 2025—2029 年,则被视为经典计算与量子计算真正开始“协同工作”的关键窗口期——混合计算标准算法、统一编程接口与中间表达层逐步成型,QPU 不再只是被远程调用的实验设备,而是以机柜级、光纤互联的方式进入数据中心,与通算、超算、智算共同组成可调度的算力池。更长远来看,随着模块化集群、全光网络互联和 QaaS 形态成熟,量子计算将不再被单独标注为一种“特殊算力”,而是深度融入通用计算体系,在优化、模拟、密码和 AI 等复杂问题中发挥其不可替代的补充作用。
这一判断,与英伟达NVQLink的逻辑高度一致:量子计算不是为了替代 GPU,而是为算力体系引入一个经典算法难以高效逼近的新维度。
为什么是“光量子”?一条更工程化的路径
在量子计算的多条技术路线中(超导、离子阱、光量子等),超导路线由于IBM、谷歌等巨头的加持显得最为“拥挤”。而图灵量子坚定地选择了光量子路径,并建成了国内首条光子芯片中试线。
据赵翔介绍,这背后至少有三层战略考量:
第一,供应链的自主可控:相比于对先进制程依赖极高的AI电子芯片,光量子芯片对制程的要求并不苛刻。“光制程不会被卡脖子”,这在当前国际技术博弈的大环境下,意义非凡。
第二,计算规模的天然优势:50个量子比特对应的矩阵维度是2^50,这一规模远超传统GPU的亿级参数量。通过薄膜铌酸锂(TFLN)——这种被誉为“光学硅”的材料,图灵量子实现了极高的调制速率(110GHz)和超低损耗,为大规模算力互联夯实了地基。
第三,系统级融合的友好性:光量子天然适合大规模并行计算,光子叠加与干涉本身就是高维矩阵运算的物理实现。而且光量子更容易与经典算力做系统级融合,尤其是在光电共封(CPO)和高速互联成熟后。
不过,图灵量子并未把“光芯片”本身作为唯一卖点。在其技术路线中,光源、探测器、测控系统与算法协同,远比单一芯片重要。这也是其同时布局薄膜铌酸锂(TFLN)与飞秒激光直写的原因:前者用于高密度、低损耗集成,后者用于构建三维光子拓扑。这种“双物理载体”策略,本质上是在为未来系统级量子计算预留弹性。
一条完整的“量子–经典混合计算”落地路径
与许多停留在单点突破的量子公司不同,图灵量子给出的是一条自下而上的全栈路径。
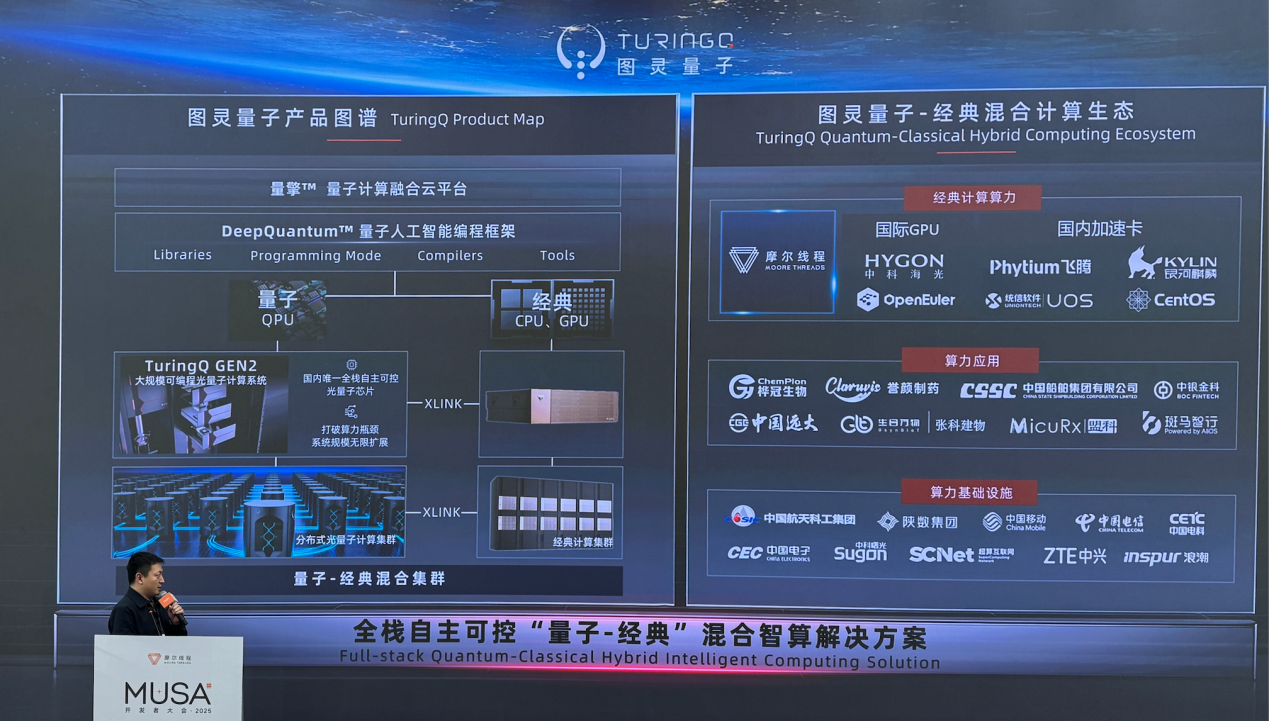
(一)在底层,是同时连接光量子 QPU 与 CPU/GPU 等经典算力资源,形成可调度的混合算力池
在芯片领域,图灵量子已完成国内罕见的、全栈自主可控的大规模高速可编程光量子芯片路径,成功打通从材料、器件到系统集成的关键链条。其核心突破集中在三项关键技术上:晶圆级薄膜铌酸锂光子芯片制备、多维飞秒激光直写三维光路结构,以及光电融合的高密度共封装工艺。
据赵博士的介绍,公司的光量子芯片在单片上实现了超过1000个的光子器件集成密度,高速电光调制带宽达到 110 GHz,器件损耗控制在 0.1 dB/cm 以下,并在单芯片上支持上千个光量子模式数运行,突破了长期制约光量子计算规模化的集成与一致性瓶颈。
在量电融合的工作中,从赵博士展示的方案来看,其基于玻璃芯基板的量电融合板卡,展现了系统级互联能力:通过玻璃芯基板与高密度通孔技术,将光子芯片、电芯片与高速光互连有机耦合,在保持尺寸稳定性与可靠性的同时,实现远高于传统有机基板的互连密度与带宽水平。某种意义上,这一量电融合板卡并不是单独面向量子计算的产品,而是为未来 QPU 与 GPU、CPU 等算力单元在同一系统内协同工作预先搭建的硬件基础设施,为量子–经典混合计算从逻辑融合走向物理融合提供了现实路径。
硬件侧,图灵量子发布的第二代大规模混合集成光量子计算机TuringQ Gen2已实现全栈自主可控。该系统以自研光量子芯片为核心,集成量子光源、量子计算网络、单光子探测与符合计数等关键模块,构建起可编程、高度可扩展的异构计算平台。性能表现上,TuringQ Gen2 突破性地实现了 56 光子相干操纵,具备超 10 万变元的复杂问题求解能力及 100+ 量子比特张量网络模拟规模。凭借 32x32 规模的薄膜铌酸锂(TFLN)芯片,其系统主频跃升至 10GHz。尤为关键的是,支持在标准 IDC 机房环境下实现多节点室温部署。
此次图灵量子与摩尔线程的量电融合解决方案就是以 TuringQ Gen2 新一代大规模混合集成光量子计算机为载体,以QPU+GPU的深度协同为核心,通过量子–经典混合计算平台与 DeepQuantum 量子计算框架,将量子算法的模拟、训练与实际执行统一纳入 GPU 可高效调度的算力体系之中。
(二)中间层:DeepQuantum,把“量子计算”变成“工程软件”
量电融合并不止于硬件。量电融合的方案基于DeepQuantum量子人工智能编程框架。
DeepQuantum是一套面向量子–经典混合计算的统一软件框架:在上层,它为开发者提供与 PyTorch 等主流 AI 框架无缝衔接的编程接口,使混合量子–经典模型能够以熟悉的方式进行构建、训练与优化;在中间层,通过 QubitCircuit 与 QumodeCircuit 两种电路抽象,同时覆盖离散变量与连续变量量子计算范式,支持从量子线路设计、噪声建模到算法映射的完整流程;在底层,则直接对接 CPU、GPU 以及光量子 QPU 等多类算力资源,实现分布式并行调度与大规模量子线路模拟。尤其值得注意的是,DeepQuantum 已将量子线路仿真、量子机器学习与混合算法运行深度绑定在同一软件体系之中,使量子计算不再是“先写算法、再找硬件”的割裂过程,而是能够像今天的 AI 训练一样,在统一框架下完成快速迭代。这种以软件为核心的设计逻辑,实际上为 QPU–GPU 融合提供了最关键的抽象层,也让量子计算第一次具备了走向工程化和规模应用的软件基础。
(三)最上层:量擎云平台,让量子算力“像云一样用”
在量子计算迈向规模化应用的过程中,真正决定其“可用性”的,往往不是单一算法或硬件能力,而是能否被纳入成熟的算力调度与运维体系。图灵量子推出的 “量擎经典–量子融合计算云平台”,正是围绕这一现实需求展开。该平台以 CPU、GPU 与 QPU 的统一管理为核心,将经典计算、量子计算及多种混合算法框架整合进同一云端环境,使量子算力第一次以“可调度资源”的形态参与实际计算任务。在功能层面,量擎平台覆盖混合算力调度、可视化与在线编程、设备资源配置管理以及多租户管理等关键能力,显著降低了异构算力的使用门槛,
最后,在生态侧,其混合计算体系已与多种国际与国产 GPU、加速卡及操作系统实现兼容,并在金融科技、生物医药、材料化学、工业仿真等应用场景中展开协同探索,同时对接数据中心与算力基础设施合作伙伴。
这种“平台 + 框架 + 系统 + 生态”的整体设计,表明图灵量子并未将量子计算定位为孤立设备,而是试图将其作为一种可工程化、可交付、可融入现有算力体系的计算能力,为量子-经典混合计算走向规模应用提供现实路径。
从“跟跑”到“并跑”:商业化拐点已至
不同于许多还停留在实验室阶段的量子初创公司,图灵量子的成绩单显示,量子计算正加速走出象牙塔。
从2022年营收50万元到2023年破千万,再到2025年上半年签署亿元订单,其商业化路径已清晰可见。据赵博士透露,营收主要来自三方面,一是量子安全,为银行等金融机构打造“抗量子密码”之盾。二是算力中心、航天科工等单位的整机交付;三是教育科研领域,用于量子计算领域的专业人才培养。
“AI如果落后国外半年,那么量子计算的差距不到一个月。” 采访中赵博士的这一判断令人振奋。在下一代计算范式的竞争中,中国企业正利用光量子路径的独特性,试图在“后摩尔时代”实现弯道超车。
结语
图灵量子与摩尔线程的联合,是国产算力从“单兵作战”转向“生态合围”的标志性事件。当国产GPU的图形渲染、AI加速能力,遇上光量子芯片的复杂问题求解能力,一个软硬一体、自主可控的“算力底座”正呼之欲出。虽然实现大规模容错计算仍有诸多工程挑战,但这一步,已经让我们在通向强人工智能和无限算力的征途中,握住了最关键的入场券。
责任编辑:duqin
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号