深入了解英伟达的Hopper架构
2022-03-29
22:33:26
来源: 互联网
点击
NVIDIA近日在GTC大会上推出的H100 GPU相比A100 GPU有6倍的运算性能提升,这并非是单纯依赖晶体管增加而来,而是结合新架构与新技术得到的成果。Hopper架构以美国计算机领域的先驱科学家 Grace Hopper 的名字命名,将取代两年前推出的 NVIDIA Ampere 架构。那么英伟达Hopper架构为何能使GPU达到如此高的性能?
那是因为,新的Hopper 架构主要有以下大创新点:

1)采用第四代Tensor core:与A100相比,芯片到芯片的速度提高了6倍;在每个 SM 基础上,与上一代16位相比,Tensor Core在等效数据类型上的MMA(矩阵乘法累加)计算速率是A100 SM 的 2 倍,在使用新的 FP8 数据类型时是 A100 的 4 倍浮点选项;稀疏性特征利用深度学习网络中的细粒度结构化稀疏性,将标准张量核心操作的性能提高一倍。
2)与 A100 相比,芯片对芯片的IEEE FP64和 FP32处理速率快 3 倍,因为每个 SM 的时钟对时钟性能提高了 2 倍,加上额外的 SM 计数和 H100 的更高时钟。
3)新的DPX 指令将动态编程算法的速度提高到A100 GPU的7倍。两个示例包括用于基因组学处理的 Smith-Waterman 算法,以及用于为机器人车队在动态仓库环境中寻找最佳路线的 Floyd-Warshall 算法。
4)新的线程块集群功能公开了跨多个 SM 的局部性控制。
5)新的异步执行功能包括一个新的张量内存加速器 (TMA)单元,它可以在全局内存和共享内存之间有效地传输大块数据。TMA 还支持集群中线程块之间的异步复制。还有一个新的异步事务屏障用于进行原子数据移动和同步。
6)256 KB 的组合共享内存和 L1 数据缓存,比 A100 大 1.33 倍。
Hopper架构的创新
具体来看,H100中新的第四代 Tensor Core 架构提供的每个 SM 的原始密集和稀疏矩阵数学吞吐量(时钟对时钟)是 A100 的两倍。它还支持 FP8、FP16、BF16、TF32、FP64 和 INT8 MMA 数据类型。新的 Tensor Cores 还具有更高效的数据管理,可节省高达30% 的操作数传输功率。
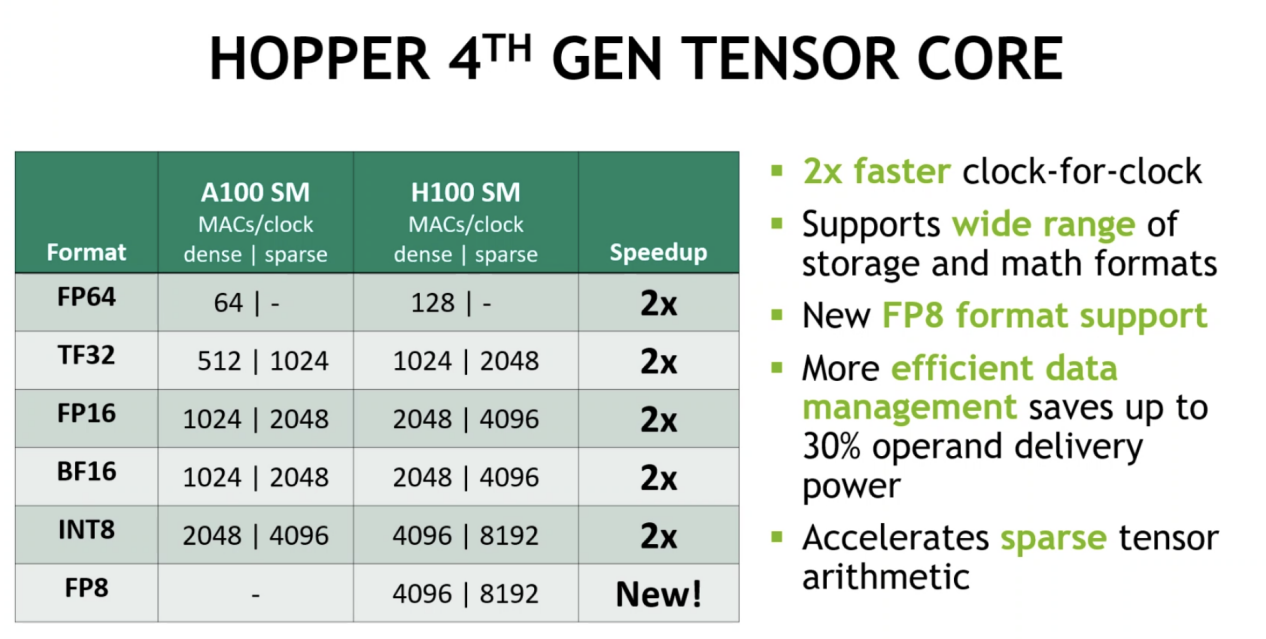
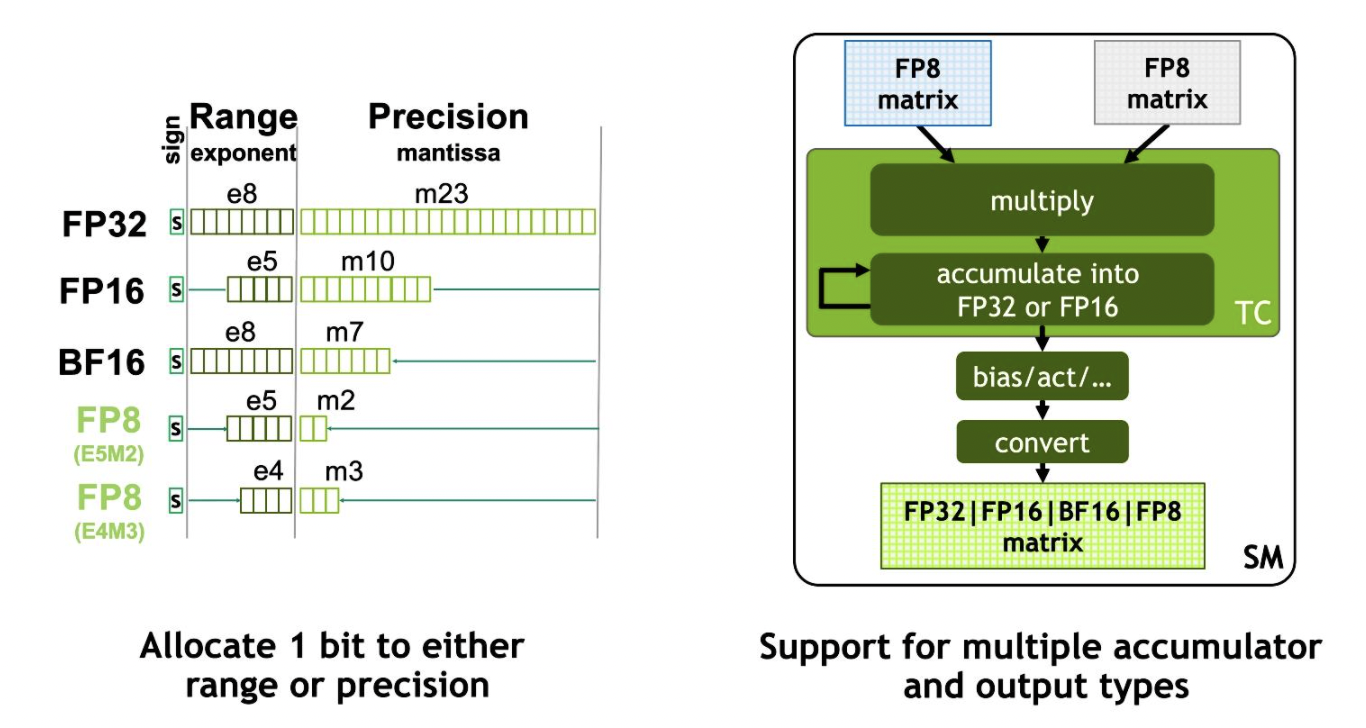
除此之外,H100 GPU还增加了FP8 Tensor Cores用来加速AI 训练和推理。FP8 Tensor Cores支持FP32和 FP16累加器,以及两种新的FP8 输入类型:E4M3 具有 4 个指数位、3 个尾数位和 1 个符号位;E5M2,具有 5 个指数位、2 个尾数位和 1 个符号位。其中,E4M3支持需要更小动态范围和更高精度的计算,而 E5M2 提供更宽的动态范围和更低的精度。与 FP16 或 BF16 相比,FP8 Tensor Cores将数据存储占用空间减半,吞吐量翻倍。
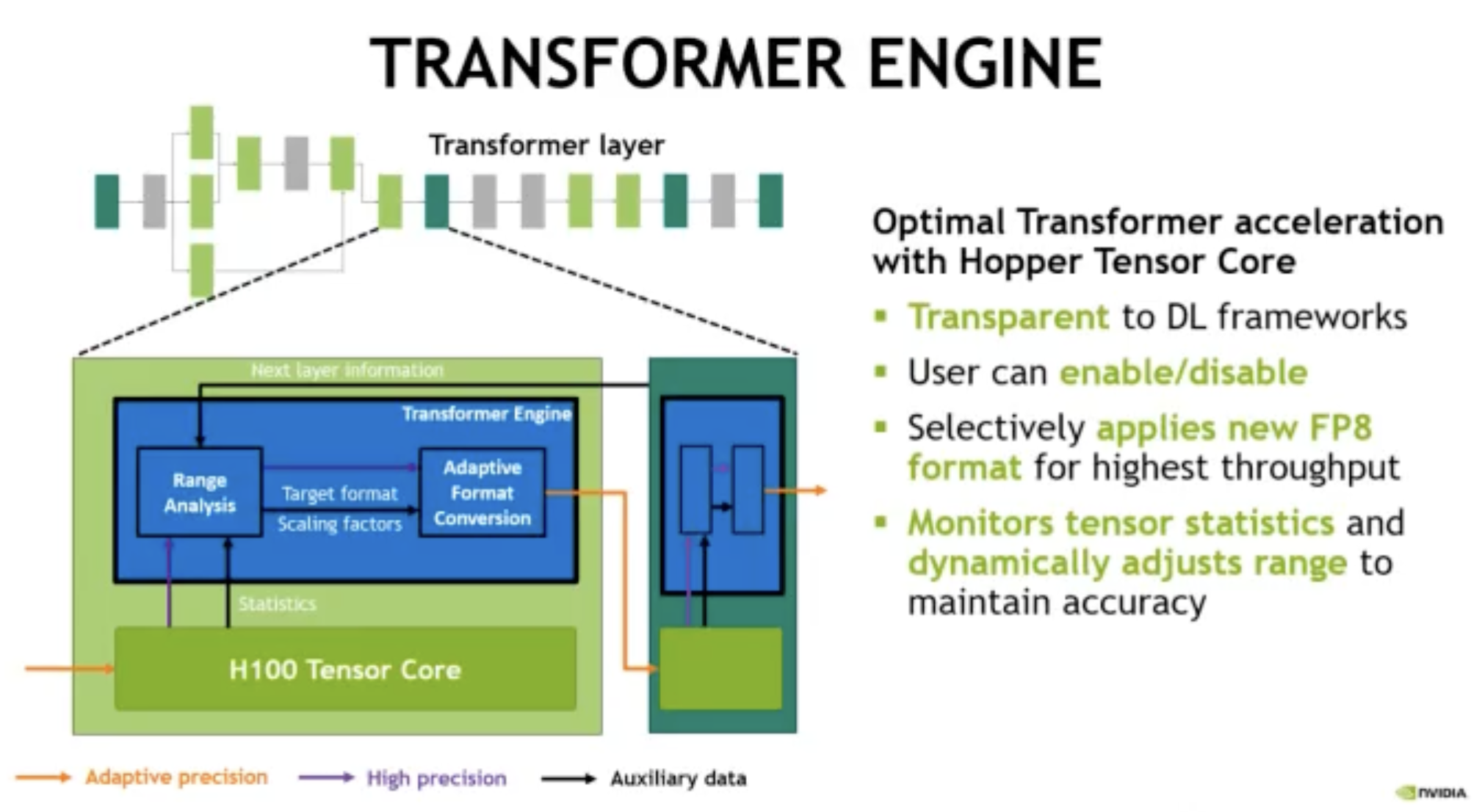
Transformer模型是当下的主流模型,是从BERT到 GPT-3都在广泛使用的语言模型。H100 包含一个新的Transformer引擎,该引擎使用软件和定制的 NVIDIA Hopper Tensor Core 技术来显着加速转换器的 AI 计算。在 Transformer模型的每一层,Transformer 引擎都会分析 Tensor Core 产生的输出值的统计数据。用户还可选择性地应用新的FP8格式以获得最高吞吐量。为了优化使用可用范围,transformer引擎还可监控张量统计并动态调整范围以保持准确性。
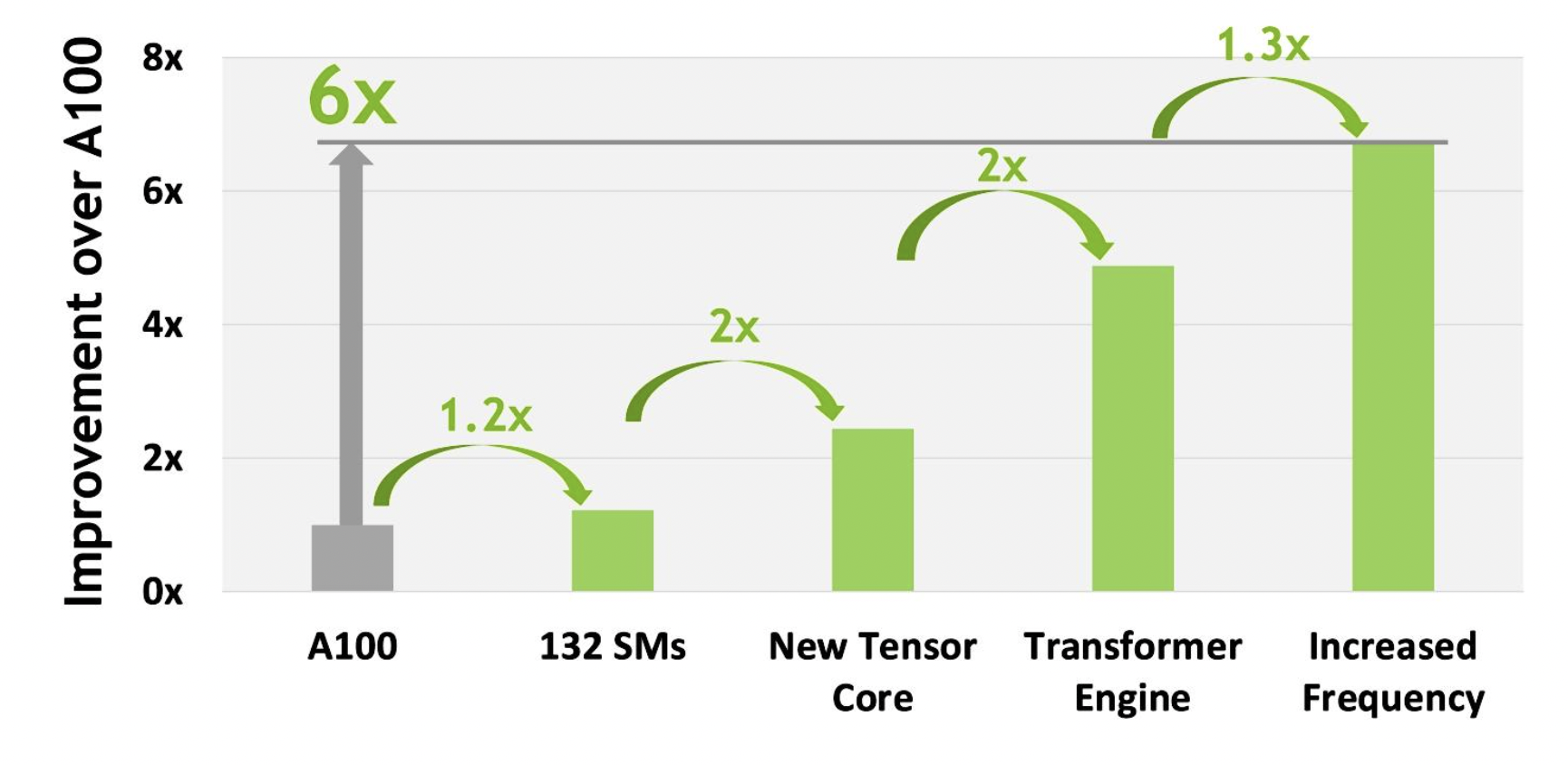
经过了上述的新的创新改进,总体作用的结果是,H100 的计算性能比 A100 提高了大约 6 倍,这在当下强大的AI计算需求下,算是一个巨大的飞跃。与 A100 108个SM 相比,计量单元增加了22%达到了个132 SM。新的第四代Tensor core使得每个H100 SM的速度都提高了2倍。在每个Tensor Core中,新的FP8 格式和相关的转换器引擎提供了另外2倍的改进。H100 中增加的时钟频率提供了大约 1.3 倍的性能提升。
 扩展之后的DGX H100系统
扩展之后的DGX H100系统通过不断的扩大AI和HPC,英伟达推出了DGX H100 系统,这是全球首个基于全新 NVIDIA H100 Tensor Core GPU 的 AI 平台。它包含八块 H100 GPU 以及总计 6400 亿个晶体管。除此之外,每个 DGX H100 系统还包含两个NVIDIA BlueField®-3 DPU,以用于卸载、加速和隔离高级网络、存储及安全服务。

A100 GPU 中的第三代 NVLink 在每个中使用四个差分对(通道)方向创建单个链路,在每个方向上提供 25 GB/秒的有效带宽。A100包括12 个第三代 NVLink 链路,可提供 600 GB/秒的总带宽。H100包括18个第四代 NVLink 链路,第四代 NVLink 在每个方向上仅使用两个高速差分对来形成单个链路,同时在每个方向上提供 25 GB/秒的有效带宽,可提供900 GB/秒的总带宽,是上一代系统的1.5倍。
新的第三代 NVSwitch 技术包括位于节点内部和外部的交换机,用于连接服务器、集群和数据中心环境中的多个 GPU。节点内每个新的第三代 NVSwitch 提供64个第四代 NVLink 链路端口,以加速多 GPU 连接。总交换机吞吐量从上一代的 7.2 Tbits/sec 增加到 13.6 Tbits/sec。NVLink 切换系统支持多达 256 个 GPU。连接的节点可以提供 57.6 TB 的全部带宽,并且可以提供FP8稀疏AI计算的 exaFLOP。
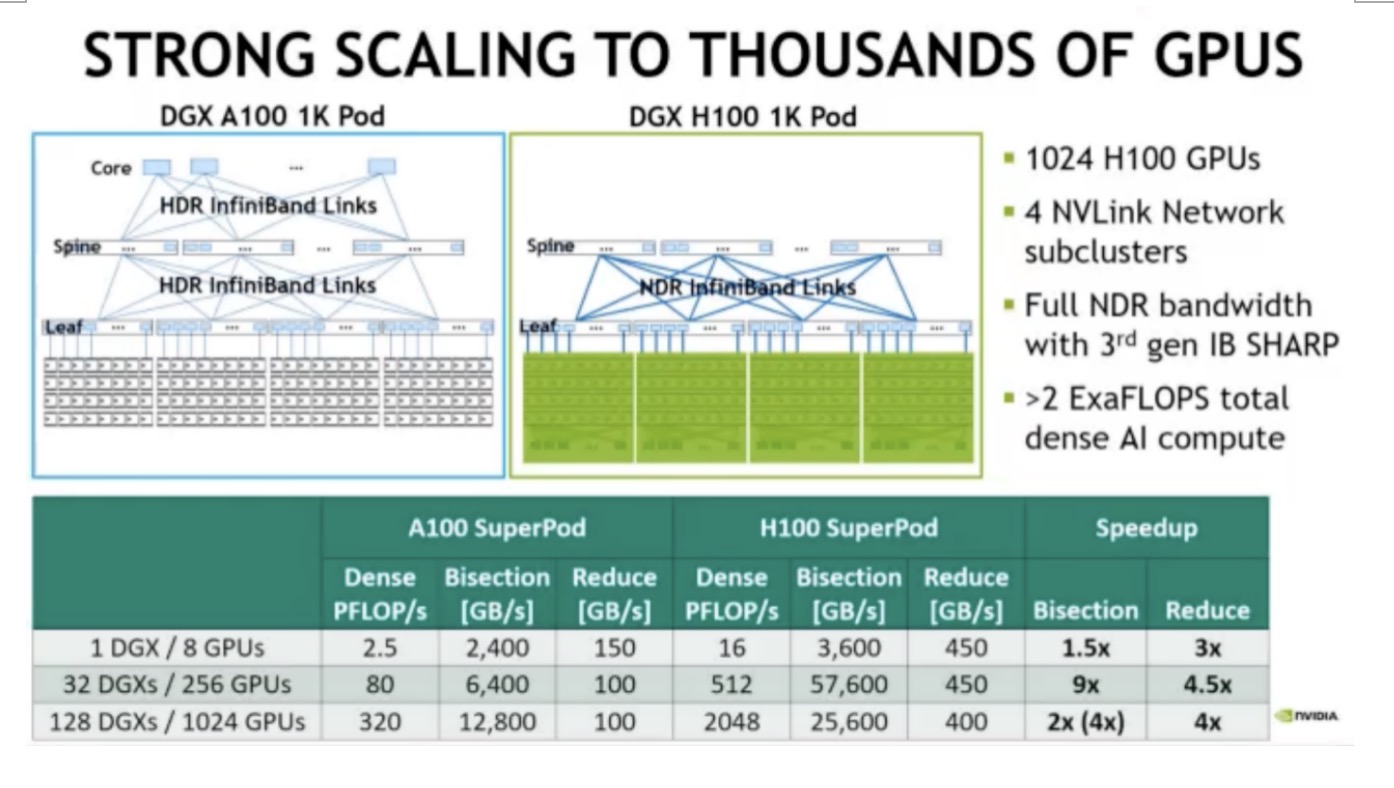
此外,新的DGX H100 SuperPOD 架构采用了一个全新的 NVIDIA NVLink Switch 系统,通过这一系统最多可连接 32 个节点,总计 256 块 H100 GPU。新一代 DGX SuperPOD 提供 1 Exaflops 的 FP8 AI 性能,比上一代产品性能高 6 倍,能够运行具有数万亿参数的庞大 LLM 工作负载,从而推动 AI 的前沿发展。
 写在最后
写在最后在摩尔定律逐渐走到极限的态势下,AI芯片的算力的提升也将面临难题,除了晶体管的叠加、工艺的先进性之外,英伟达在架构创新上的努力,或将继续在助其AI时代继续大杀四方。
责任编辑:sophie
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号