光传输,迈向3.2T!
2025-04-23
16:37:15
来源: 杜芹
点击
2025年,AI大模型赛道竞争白热化。以ChatGPT、Grok、DeepSeek与Gemini为代表的全球四大主流通用语言模型,正经历一场前所未有的技术迭代与商业格局重塑。
ChatGPT依托封闭的MoE(Mixture of Experts)架构构建出领先的多模态生态体系,其成熟的API服务体系已占营收的70%,展现出极强的变现能力;Grok则以动态推理网络为核心,主打实时数据响应,并通过与X平台深度捆绑实现商业化突破;DeepSeek以开源模型为基础,针对中文场景深度优化,广泛部署于政企私有化系统中,快速拓展本地市场;Gemini则依托Google Pathways系统,具备强大的算力基座,且已深度集成至Workspace生态,打通了办公与AI应用的边界。
在这场大模型技术与生态竞速的背后,是AI巨头们在2025年持续加码的资本投入与算力争夺。而AI应用对高速、低延迟数据交互的需求,也正成为推动光通信技术快速演进的关键驱动力。
4月23日,在第三届九峰山论坛暨化合物半导体产业博览会的下午论坛上,华工正源光子技术有限公司总经理胡长飞发表了《光速智变:解码DSP Base、LPO/LRO、NPO/CPO,迈向3.2T的光传输技术驱动AI算力跃迁》主题演讲。
光模块,AI的赋能者
如果将AI比作一个人,GPU无疑是AI的“心脏”,LLM(大规模语言模型)则是AI的“大脑”,而数据是AI的“血液”。在这个类比中,光模块便是AI的“动脉”,是确保数据在AI系统中高效流动的核心部件。光模块不仅是AI的赋能者,它的作用日益凸显,特别是在大规模计算和数据传输中,起到了至关重要的作用。
作为AI系统的动脉,光模块通过高速、低能耗、低延时的连接方式,确保了海量数据在神经网络中快速流动,进而促进GPU强大计算能力的发挥,使得大模型和新算法得以验证,从而推动AI技术的快速发展。
在Spine-Leaf-TOR(Top of Rack)架构中,光互联技术可以将GPU扩展到上万甚至十万卡的集群。这种高速连接使得AI系统能够在大规模计算中高效工作,为高性能计算提供了强有力的支撑。
光模块,加速演进
随着对数据传输速率和网络可靠性的要求不断提高,光模块的设计正在不断优化与革新。传统的网络交换机和光模块设计通常依赖多个独立的组件,使用复杂的光纤连接方式进行数据传输。尽管这种设计在早期能够满足数据传输的需求,但随着网络规模的扩大以及数据处理能力的增加,传统的分散设计逐渐暴露出局限性,亟需更高效的解决方案。
集成硅光子(SiPh)模块技术应运而生,它通过将多个光学功能集成到单一的封装中,显著简化了模块的结构。与传统设计相比,集成硅光模块减少了约30%的零部件数量,从而降低了成本,提升了可靠性,并大幅提高了传输效率。同时,基于InP/GaAs化合物半导体的高速光芯片,成为了高速连接的核心驱动。
光模块的技术演进路径,逐渐从当前的单波长100G、400G、800G DR4/DR8技术,向未来单波长200G、400G 3.2T DR8/2xFR4技术,以及共封装(CPO)单波长100G、200G的MRM DR/FR Trx技术发展。这一演变不仅代表了传输速率的提升,还反映了光模块在集成度、成本、功耗等方面的不断优化。
目前,光模块的主要技术路线包括DPO(Digital Optical Process)、LPO(Low Power Optical)、NPO(New Power Optical)和CPO(Co-Packaged Optics)。其中,DSP基于的DPO技术具备MPI检测和回环功能,适用于问题排查,但并非每个应用场景都必须采用这些功能。LPO和CPO则需要通过ASIC芯片实现MPI检测功能,且CPO的电气通道长度较短,功耗相对较低。
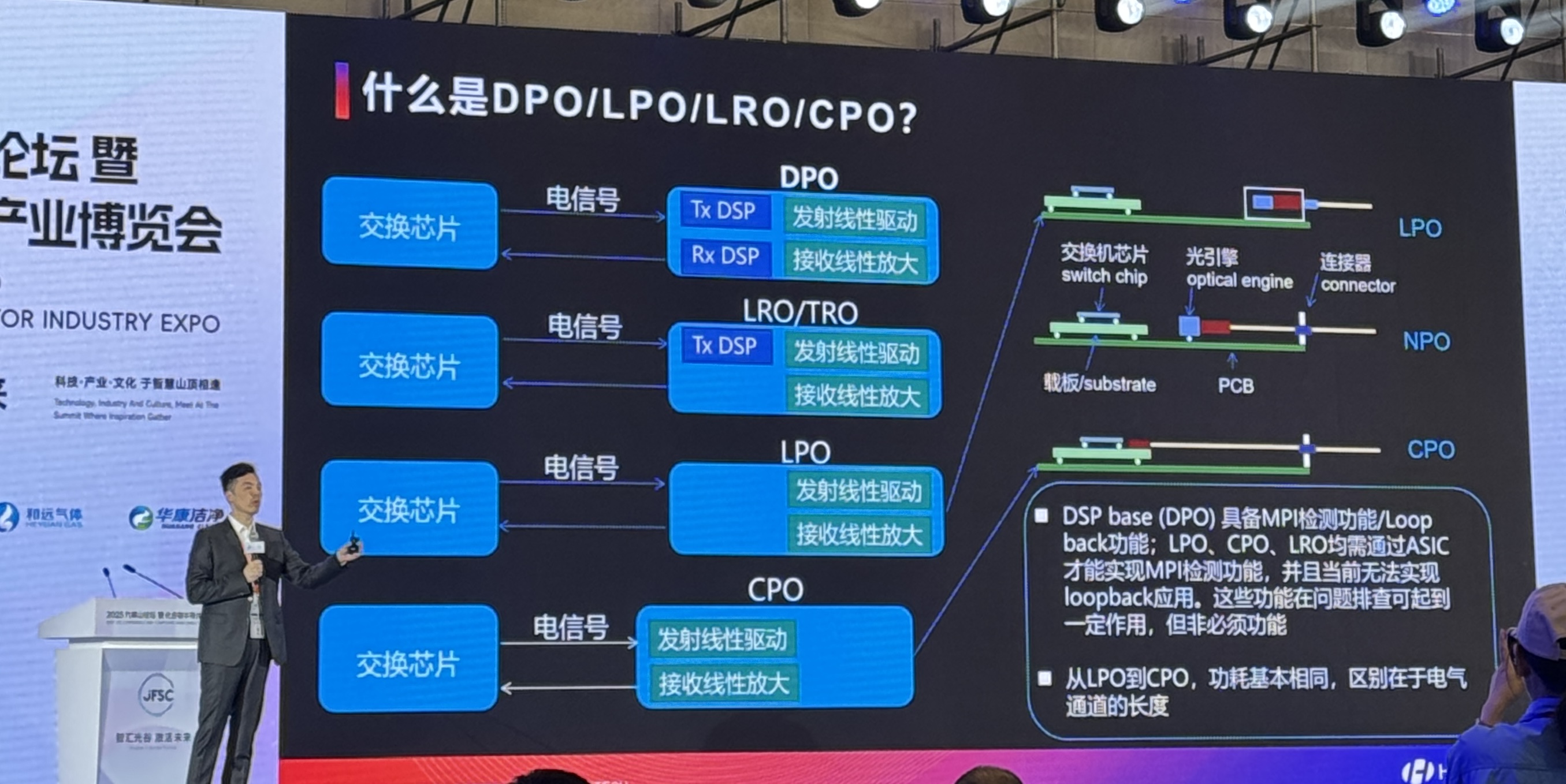
从DPO到CPO,光模块的功耗呈现出显著差异,以1.6T DR8模块为参考,DPO的功耗最高,大约为25W,而LPO功耗约为15W,CPO和LPO的功耗相对较低,通常在10W左右,体现了CPO技术的明显优势。
共封装光学技术(CPO)被视为最具潜力的光互连技术。英伟达(NVIDIA)已经在其InfiniBand和以太网交换机中引入了CPO技术,接下来NVLink交换机是否也会采用共封装光学技术成为业界关注的重点。
值得一提的是,作为全球排名前八的光模块厂商,华工正源正在研发3.2T CPO模块,华工正源的这一技术进展将为光通信领域带来深远影响。
ChatGPT依托封闭的MoE(Mixture of Experts)架构构建出领先的多模态生态体系,其成熟的API服务体系已占营收的70%,展现出极强的变现能力;Grok则以动态推理网络为核心,主打实时数据响应,并通过与X平台深度捆绑实现商业化突破;DeepSeek以开源模型为基础,针对中文场景深度优化,广泛部署于政企私有化系统中,快速拓展本地市场;Gemini则依托Google Pathways系统,具备强大的算力基座,且已深度集成至Workspace生态,打通了办公与AI应用的边界。
在这场大模型技术与生态竞速的背后,是AI巨头们在2025年持续加码的资本投入与算力争夺。而AI应用对高速、低延迟数据交互的需求,也正成为推动光通信技术快速演进的关键驱动力。
4月23日,在第三届九峰山论坛暨化合物半导体产业博览会的下午论坛上,华工正源光子技术有限公司总经理胡长飞发表了《光速智变:解码DSP Base、LPO/LRO、NPO/CPO,迈向3.2T的光传输技术驱动AI算力跃迁》主题演讲。
光模块,AI的赋能者
如果将AI比作一个人,GPU无疑是AI的“心脏”,LLM(大规模语言模型)则是AI的“大脑”,而数据是AI的“血液”。在这个类比中,光模块便是AI的“动脉”,是确保数据在AI系统中高效流动的核心部件。光模块不仅是AI的赋能者,它的作用日益凸显,特别是在大规模计算和数据传输中,起到了至关重要的作用。
作为AI系统的动脉,光模块通过高速、低能耗、低延时的连接方式,确保了海量数据在神经网络中快速流动,进而促进GPU强大计算能力的发挥,使得大模型和新算法得以验证,从而推动AI技术的快速发展。
在Spine-Leaf-TOR(Top of Rack)架构中,光互联技术可以将GPU扩展到上万甚至十万卡的集群。这种高速连接使得AI系统能够在大规模计算中高效工作,为高性能计算提供了强有力的支撑。
光模块,加速演进
随着对数据传输速率和网络可靠性的要求不断提高,光模块的设计正在不断优化与革新。传统的网络交换机和光模块设计通常依赖多个独立的组件,使用复杂的光纤连接方式进行数据传输。尽管这种设计在早期能够满足数据传输的需求,但随着网络规模的扩大以及数据处理能力的增加,传统的分散设计逐渐暴露出局限性,亟需更高效的解决方案。
集成硅光子(SiPh)模块技术应运而生,它通过将多个光学功能集成到单一的封装中,显著简化了模块的结构。与传统设计相比,集成硅光模块减少了约30%的零部件数量,从而降低了成本,提升了可靠性,并大幅提高了传输效率。同时,基于InP/GaAs化合物半导体的高速光芯片,成为了高速连接的核心驱动。
光模块的技术演进路径,逐渐从当前的单波长100G、400G、800G DR4/DR8技术,向未来单波长200G、400G 3.2T DR8/2xFR4技术,以及共封装(CPO)单波长100G、200G的MRM DR/FR Trx技术发展。这一演变不仅代表了传输速率的提升,还反映了光模块在集成度、成本、功耗等方面的不断优化。
目前,光模块的主要技术路线包括DPO(Digital Optical Process)、LPO(Low Power Optical)、NPO(New Power Optical)和CPO(Co-Packaged Optics)。其中,DSP基于的DPO技术具备MPI检测和回环功能,适用于问题排查,但并非每个应用场景都必须采用这些功能。LPO和CPO则需要通过ASIC芯片实现MPI检测功能,且CPO的电气通道长度较短,功耗相对较低。
从DPO到CPO,光模块的功耗呈现出显著差异,以1.6T DR8模块为参考,DPO的功耗最高,大约为25W,而LPO功耗约为15W,CPO和LPO的功耗相对较低,通常在10W左右,体现了CPO技术的明显优势。
共封装光学技术(CPO)被视为最具潜力的光互连技术。英伟达(NVIDIA)已经在其InfiniBand和以太网交换机中引入了CPO技术,接下来NVLink交换机是否也会采用共封装光学技术成为业界关注的重点。
值得一提的是,作为全球排名前八的光模块厂商,华工正源正在研发3.2T CPO模块,华工正源的这一技术进展将为光通信领域带来深远影响。
责任编辑:admin
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号