Arm发布《芯片新思维:人工智能时代的新根基》行业报告
2025-04-24
10:56:57
来源: 杜芹
点击
半导体产业正处在前所未有之大变局时刻:一方面,摩尔定律渐趋极限;另一方面,人工智能的爆发式增长对计算架构带来全新的机遇与挑战。面对这一趋势,Arm 于近期发布《芯片新思维:人工智能时代的新根基》行业报告,该报告汇集了构建AI时代芯片设计新范式的洞察,涵盖算力、能效、安全、可扩展性等核心议题,勾勒出未来智能计算的底层路线图。
在该报告中,Arm与业界专家分享了诸多关键趋势:
·通过摩尔定律实现半导体缩放的传统方法已达到物理与经济的极限。产业正转向创新的替代方案,如定制芯片、计算子系统 (CSS) 以及芯粒 (chiplets),以持续提升性能与能效。
·随着 AI 工作负载对计算密集型任务的需求日益增加,能效已成为 AI 计算发展的首要考量。芯片设计正在整合优化的内存层次结构、先进的封装技术,以及成熟的电源管理技术,以降低能源消耗,同时维持高性能。
·安全威胁随着 AI 技术的发展也在同步演进,其中 AI 驱动的网络攻击为各行各业带来新的挑战。半导体产业正在积极构建多层次的软硬件防护体系,从嵌入式芯片加密技术,到经 AI 强化的安全监测系统,以应对新兴的安全威胁。
·芯片设计本身正在经历根本性的变革。以往,芯片设计与制造环节相对独立,保持着一定距离,然而,随着新的工艺节点要求整个生态系统更深入的合作,使得芯片设计与制造之间的关联更为紧密。与此同时,用于芯粒的先进封装技术,正在成为推动未来创新的关键驱动力。
·软件生态系统仍然是释放新芯片架构潜力的关键。在保障与 AI 框架无缝兼容的同时,为定制芯片提供优化支持,是实现新型芯片架构普及的关键所在。
AI计算底层逻辑发生质变
过去四十年,芯片技术经历了从早期的超大规模集成电路 (VLSI) 和极大规模集成电路 (ULSI) 设计、移动芯片组的发展,到移动系统级芯片 (SoC) 的广泛应用,再到如今的 AI 优化的定制芯片解决方案的深刻演进,这些技术也成为了支撑 AI 时代计算处理的关键。在这一过程中,每一次技术跃迁都深刻影响了芯片架构的设计逻辑与产业策略。
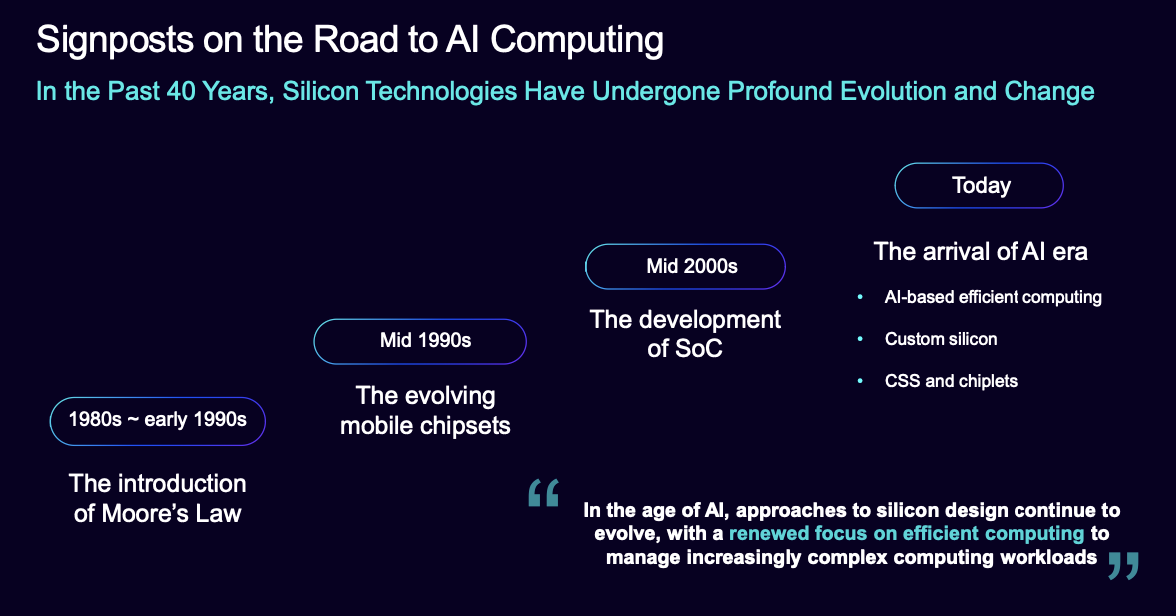
上世纪80年代至 90 年代初,摩尔定律的提出开启了晶体管数量指数级增长的黄金时代。通过持续缩小工艺节点,行业得以在不增加面积的前提下大幅提升计算能力,这是通用处理器快速崛起的基础。
进入 1990 年代中期,移动芯片的兴起对芯片设计提出了“性能-功耗-体积”的三重挑战,推动了更为精细化的架构调优和能效控制。
2000 年代中期,系统级芯片(System on Chip, SoC)的发展标志着架构整合的到来。CPU、GPU、ISP 等多个电子组件被集成于单一芯片,这使得如今的智能手机与其他移动设备能够支持广泛的应用与服务。
而今天,行业已经全面迈入以 AI 为核心驱动的计算时代。当前芯片技术的发展集中体现为三个方向:
l 基于 AI 的高能效计算:强调从架构到工艺全面优化 AI 推理与训练的能效比;
l 定制芯片的广泛采用:企业根据特定业务需求进行算力定制,获得更高的性价比与差异化能力;
l 计算子系统(CSS)和芯粒(chiplets)技术的崛起:通过 CSS 与标准化芯粒构建模块化 SoC,提升可扩展性与开发效率。
正如 Arm 在报告中所指出的:“在 AI 时代,芯片的设计方法持续演进,重新聚焦于高效计算,以应对日益复杂的计算工作负载。” 这意味着从晶体管级别的优化,到系统级封装的异构设计,再到生态层级的软件协同,每一个环节都在重塑 AI 计算的底层逻辑。
定制芯片兴起:云巨头的下一场算力竞赛
在人工智能席卷各行业的背景下,定制芯片成为满足多样化场景需求的重要解法。如今,几乎所有的半导体行业从业者都在探索和投资定制芯片,特别是全球四大超大规模云服务提供商,他们在 2024 年全球云服务器采购支出中占了近半数的份额。
定制芯片的崛起与Arm架构有着密切的关系。2023年,微软发布了首款面向云端定制的芯片 Microsoft Azure Cobalt,该芯片选用了 Arm Neoverse CSS 进行打造,旨在应对复杂的计算基础设施挑战。近期,Google Cloud 也发布了基于 Arm Neoverse 平台的 Axion 定制芯片,专为应对数据中心复杂的服务器工作负载而设计。
Arm解决方案工程部执行副总裁 Kevork Kechichian指出,定制不等于一切从零开始。他强调,定制芯片设计的关键在于确保芯片与软件具备高度的可复用性。比如,Arm Neoverse CSS 经过验证的核心计算功能以及灵活的内存与 I/O 接口配置,能够加快产品上市进程,并在确保软件一致性的同时,为 SoC 设计人员提供了灵活性,使其能够基于 CSS 周围新增定制子系统,打造差异化的解决方案。
与此同时,AI 推理正从云端向端侧持续下沉。在谈到在云端进行模型训练与在边缘设备上运行推理的趋势时,Kevork 强调:“一旦模型在云端利用海量数据集完成训练,就可以进行优化,使其能够运行在较小的服务器,甚至是边缘设备上,从而提升数据传输效率和整体性能。”
Kevork进一步指出,Arm 聚焦于异构计算,该范式中的 CPU、GPU 、TPU以及其他 AI 加速器能够支持不同的工作负载,所有这些处理器都可以作为 AI 推理的处理引擎,部署到 Arm 合作伙伴所开发的 SoC 中。”
Chiplet为定制芯片铺平道路
Chiplet(芯粒)正在成为推动定制芯片普及的重要驱动技术。理想情况下,芯片厂商无需重新设计一款芯片,只需添加更多芯粒以增加算力和性能,甚至可以升级现有芯粒,从而更快地将新产品推向市场。与此同时,生产更小的芯片还有助于提高良率,并减少制造过程中的浪费。
将系统拆分为芯粒,并通过并排或 3D 堆叠方式进行集成,为行业带来了诸多新机遇。这些机遇包括:一、更大的设计灵活性:能够根据不同应用场景打造差异化的设计方案;二、功能优化能力:能够针对特定功能对不同组件进行优化;三、优化的生产良率:通过制造更小的晶粒提升良品率;四、更大的产品复用潜力:可在不同产品之间实现更高的复用潜力。
该报告指出,芯片设计向芯粒架构转型的趋势,本质上并非为了追求小型化。事实上,随着逻辑门数量的增长速度已超越单纯依靠缩放技术所能支撑的极限,系统整体尺寸仍在持续增大。
在谈到芯粒技术的挑战时,Kevork明确表示:“最关键的是如何对芯粒的设计与接口方式进行标准化。”Arm 正推动其芯粒系统架构(CSA)成为业界标准,并携手合作伙伴共同推动 AMBA CHI 芯片到芯片互连协议等倡议的落地实施,确保来自不同供应商的不同芯粒通过一个统一的接口协议来确保芯粒之间的互操作性。
他还强调,先进封装与芯粒技术的真正价值在于实现真正的标准化。通过标准化,企业可以根据不同的性能需求,快速地组合和配置这些芯粒,从而打造出具有不同性能定位的芯片。这不仅大大缩短了产品上市周期,也能确保在快速迭代的市场竞争中占据先机。
算力和能效,如何兼而得之?
AI工作负载的计算需求极大,需要大量电力与能源资源来支持其运行,且这种需求在未来将会持续增长。从芯片设计的角度来看,最主要的能耗来源有两个:计算和数据传输。此外,还需要对过程中所产生的热量进行冷却处理。
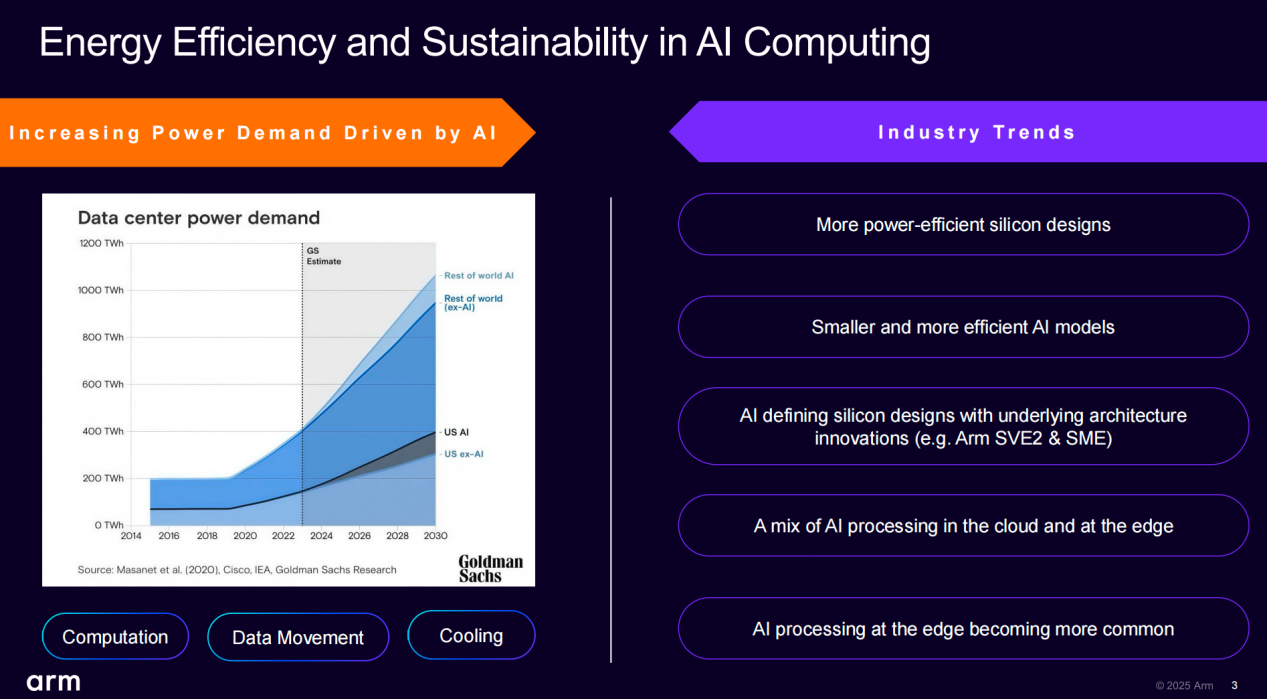
Arm 在报告中指出,全球范围内的‘AI 主导权’争夺战,正推动大量资金投入到规模日益庞大的模型训练中。然而,这种依赖算力堆砌的‘蛮力式’发展路径在经济上难以为继,由此催生了对更智能、更高能效的芯片解决方案的迫切需求。
针对当前 AI 发展对算力与能效提出的双重挑战,Kevork 描绘了一条“全栈式优化路径”——从晶体管层开始,与晶圆代工厂紧密协作,确保晶体管在性能以及动态功耗与漏电功耗方面实现优化;再到架构层面,对 CPU 以及各类处理引擎的指令集进行针对性优化;然后再到系统级芯片 (SoC) 设计、封装到数据中心等方面的优化。最后,在支撑大型数据中心运行的软件层,实现智能负载均衡,尽可能减少不同节点之间的数据传输。
芯片设计成功的几大要素
展望未来,Arm认为,芯片设计的成功将越来越依赖于以下几点:1)IP 提供商、晶圆代工厂与系统集成商之间的紧密合作;2)计算、内存与电源传输之间的系统级优化;3)接口的标准化,以支持模块化设计;4)针对特定工作负载的专用架构;5)能灵活应对新兴威胁的强大安全框架。
AI 时代的软硬件生态不再割裂。Kevork 认为构建和维护认为可持续生态系统的关键在于充分激发并整合各方在不同领域的核心专长。从晶圆代工厂到各类 IP 提供商,从服务提供商到仿真平台,整个产业链需要基于标准与复用建立正循环。
同时,面对日益复杂的网络安全威胁,Arm 正在通过构建多层级的软硬件防护体系,提升防御能力。Arm 在芯片中直接集成加密技术,并结合经 AI 强化的安全监测系统,使现代 SoC 架构能够抵御传统攻击与新兴的威胁。此外,Kevork 还表示,“AI 本身也正日益成为抵御安全攻击的有力助手。通过基于网络的监测与先进的代码分析,AI 驱动的技术能够以人类难以企及的速度和规模识别可疑行为,并发现潜在漏洞,而 Arm 正在最大限度地发挥这一优势。”
结语
在这场 AI 计算范式的根本性转变中,Arm 以其深厚的 SoC 设计及计算平台开发能力、标准化生态体系以及开放式合作策略,正在为行业打造坚实的新根基。
从移动芯片到数据中心,从定制芯片到芯粒系统,Arm 不仅见证了过去四十年的芯片技术跃迁,也正以平台化的姿态引领下一代 AI 计算架构的演进。相信未来,Arm 也将继续携手生态各方,共同推动智能计算的广泛普及与持续创新。
在该报告中,Arm与业界专家分享了诸多关键趋势:
·通过摩尔定律实现半导体缩放的传统方法已达到物理与经济的极限。产业正转向创新的替代方案,如定制芯片、计算子系统 (CSS) 以及芯粒 (chiplets),以持续提升性能与能效。
·随着 AI 工作负载对计算密集型任务的需求日益增加,能效已成为 AI 计算发展的首要考量。芯片设计正在整合优化的内存层次结构、先进的封装技术,以及成熟的电源管理技术,以降低能源消耗,同时维持高性能。
·安全威胁随着 AI 技术的发展也在同步演进,其中 AI 驱动的网络攻击为各行各业带来新的挑战。半导体产业正在积极构建多层次的软硬件防护体系,从嵌入式芯片加密技术,到经 AI 强化的安全监测系统,以应对新兴的安全威胁。
·芯片设计本身正在经历根本性的变革。以往,芯片设计与制造环节相对独立,保持着一定距离,然而,随着新的工艺节点要求整个生态系统更深入的合作,使得芯片设计与制造之间的关联更为紧密。与此同时,用于芯粒的先进封装技术,正在成为推动未来创新的关键驱动力。
·软件生态系统仍然是释放新芯片架构潜力的关键。在保障与 AI 框架无缝兼容的同时,为定制芯片提供优化支持,是实现新型芯片架构普及的关键所在。
AI计算底层逻辑发生质变
过去四十年,芯片技术经历了从早期的超大规模集成电路 (VLSI) 和极大规模集成电路 (ULSI) 设计、移动芯片组的发展,到移动系统级芯片 (SoC) 的广泛应用,再到如今的 AI 优化的定制芯片解决方案的深刻演进,这些技术也成为了支撑 AI 时代计算处理的关键。在这一过程中,每一次技术跃迁都深刻影响了芯片架构的设计逻辑与产业策略。
上世纪80年代至 90 年代初,摩尔定律的提出开启了晶体管数量指数级增长的黄金时代。通过持续缩小工艺节点,行业得以在不增加面积的前提下大幅提升计算能力,这是通用处理器快速崛起的基础。
进入 1990 年代中期,移动芯片的兴起对芯片设计提出了“性能-功耗-体积”的三重挑战,推动了更为精细化的架构调优和能效控制。
2000 年代中期,系统级芯片(System on Chip, SoC)的发展标志着架构整合的到来。CPU、GPU、ISP 等多个电子组件被集成于单一芯片,这使得如今的智能手机与其他移动设备能够支持广泛的应用与服务。
而今天,行业已经全面迈入以 AI 为核心驱动的计算时代。当前芯片技术的发展集中体现为三个方向:
l 基于 AI 的高能效计算:强调从架构到工艺全面优化 AI 推理与训练的能效比;
l 定制芯片的广泛采用:企业根据特定业务需求进行算力定制,获得更高的性价比与差异化能力;
l 计算子系统(CSS)和芯粒(chiplets)技术的崛起:通过 CSS 与标准化芯粒构建模块化 SoC,提升可扩展性与开发效率。
正如 Arm 在报告中所指出的:“在 AI 时代,芯片的设计方法持续演进,重新聚焦于高效计算,以应对日益复杂的计算工作负载。” 这意味着从晶体管级别的优化,到系统级封装的异构设计,再到生态层级的软件协同,每一个环节都在重塑 AI 计算的底层逻辑。
定制芯片兴起:云巨头的下一场算力竞赛
在人工智能席卷各行业的背景下,定制芯片成为满足多样化场景需求的重要解法。如今,几乎所有的半导体行业从业者都在探索和投资定制芯片,特别是全球四大超大规模云服务提供商,他们在 2024 年全球云服务器采购支出中占了近半数的份额。
定制芯片的崛起与Arm架构有着密切的关系。2023年,微软发布了首款面向云端定制的芯片 Microsoft Azure Cobalt,该芯片选用了 Arm Neoverse CSS 进行打造,旨在应对复杂的计算基础设施挑战。近期,Google Cloud 也发布了基于 Arm Neoverse 平台的 Axion 定制芯片,专为应对数据中心复杂的服务器工作负载而设计。
Arm解决方案工程部执行副总裁 Kevork Kechichian指出,定制不等于一切从零开始。他强调,定制芯片设计的关键在于确保芯片与软件具备高度的可复用性。比如,Arm Neoverse CSS 经过验证的核心计算功能以及灵活的内存与 I/O 接口配置,能够加快产品上市进程,并在确保软件一致性的同时,为 SoC 设计人员提供了灵活性,使其能够基于 CSS 周围新增定制子系统,打造差异化的解决方案。
与此同时,AI 推理正从云端向端侧持续下沉。在谈到在云端进行模型训练与在边缘设备上运行推理的趋势时,Kevork 强调:“一旦模型在云端利用海量数据集完成训练,就可以进行优化,使其能够运行在较小的服务器,甚至是边缘设备上,从而提升数据传输效率和整体性能。”
Kevork进一步指出,Arm 聚焦于异构计算,该范式中的 CPU、GPU 、TPU以及其他 AI 加速器能够支持不同的工作负载,所有这些处理器都可以作为 AI 推理的处理引擎,部署到 Arm 合作伙伴所开发的 SoC 中。”
Chiplet为定制芯片铺平道路
Chiplet(芯粒)正在成为推动定制芯片普及的重要驱动技术。理想情况下,芯片厂商无需重新设计一款芯片,只需添加更多芯粒以增加算力和性能,甚至可以升级现有芯粒,从而更快地将新产品推向市场。与此同时,生产更小的芯片还有助于提高良率,并减少制造过程中的浪费。
将系统拆分为芯粒,并通过并排或 3D 堆叠方式进行集成,为行业带来了诸多新机遇。这些机遇包括:一、更大的设计灵活性:能够根据不同应用场景打造差异化的设计方案;二、功能优化能力:能够针对特定功能对不同组件进行优化;三、优化的生产良率:通过制造更小的晶粒提升良品率;四、更大的产品复用潜力:可在不同产品之间实现更高的复用潜力。
该报告指出,芯片设计向芯粒架构转型的趋势,本质上并非为了追求小型化。事实上,随着逻辑门数量的增长速度已超越单纯依靠缩放技术所能支撑的极限,系统整体尺寸仍在持续增大。
在谈到芯粒技术的挑战时,Kevork明确表示:“最关键的是如何对芯粒的设计与接口方式进行标准化。”Arm 正推动其芯粒系统架构(CSA)成为业界标准,并携手合作伙伴共同推动 AMBA CHI 芯片到芯片互连协议等倡议的落地实施,确保来自不同供应商的不同芯粒通过一个统一的接口协议来确保芯粒之间的互操作性。
他还强调,先进封装与芯粒技术的真正价值在于实现真正的标准化。通过标准化,企业可以根据不同的性能需求,快速地组合和配置这些芯粒,从而打造出具有不同性能定位的芯片。这不仅大大缩短了产品上市周期,也能确保在快速迭代的市场竞争中占据先机。
算力和能效,如何兼而得之?
AI工作负载的计算需求极大,需要大量电力与能源资源来支持其运行,且这种需求在未来将会持续增长。从芯片设计的角度来看,最主要的能耗来源有两个:计算和数据传输。此外,还需要对过程中所产生的热量进行冷却处理。
Arm 在报告中指出,全球范围内的‘AI 主导权’争夺战,正推动大量资金投入到规模日益庞大的模型训练中。然而,这种依赖算力堆砌的‘蛮力式’发展路径在经济上难以为继,由此催生了对更智能、更高能效的芯片解决方案的迫切需求。
针对当前 AI 发展对算力与能效提出的双重挑战,Kevork 描绘了一条“全栈式优化路径”——从晶体管层开始,与晶圆代工厂紧密协作,确保晶体管在性能以及动态功耗与漏电功耗方面实现优化;再到架构层面,对 CPU 以及各类处理引擎的指令集进行针对性优化;然后再到系统级芯片 (SoC) 设计、封装到数据中心等方面的优化。最后,在支撑大型数据中心运行的软件层,实现智能负载均衡,尽可能减少不同节点之间的数据传输。
芯片设计成功的几大要素
展望未来,Arm认为,芯片设计的成功将越来越依赖于以下几点:1)IP 提供商、晶圆代工厂与系统集成商之间的紧密合作;2)计算、内存与电源传输之间的系统级优化;3)接口的标准化,以支持模块化设计;4)针对特定工作负载的专用架构;5)能灵活应对新兴威胁的强大安全框架。
AI 时代的软硬件生态不再割裂。Kevork 认为构建和维护认为可持续生态系统的关键在于充分激发并整合各方在不同领域的核心专长。从晶圆代工厂到各类 IP 提供商,从服务提供商到仿真平台,整个产业链需要基于标准与复用建立正循环。
同时,面对日益复杂的网络安全威胁,Arm 正在通过构建多层级的软硬件防护体系,提升防御能力。Arm 在芯片中直接集成加密技术,并结合经 AI 强化的安全监测系统,使现代 SoC 架构能够抵御传统攻击与新兴的威胁。此外,Kevork 还表示,“AI 本身也正日益成为抵御安全攻击的有力助手。通过基于网络的监测与先进的代码分析,AI 驱动的技术能够以人类难以企及的速度和规模识别可疑行为,并发现潜在漏洞,而 Arm 正在最大限度地发挥这一优势。”
结语
在这场 AI 计算范式的根本性转变中,Arm 以其深厚的 SoC 设计及计算平台开发能力、标准化生态体系以及开放式合作策略,正在为行业打造坚实的新根基。
从移动芯片到数据中心,从定制芯片到芯粒系统,Arm 不仅见证了过去四十年的芯片技术跃迁,也正以平台化的姿态引领下一代 AI 计算架构的演进。相信未来,Arm 也将继续携手生态各方,共同推动智能计算的广泛普及与持续创新。
责任编辑:admin
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号