NVIDIA发布开源大模型Nemotron 3:正面挑战“不可能三角”
2025-12-16
15:41:34
来源: 杜芹
点击
当生成式 AI 走过能力爆发期,真正进入企业落地的“深水区”,模型竞争的规则已经发生变化。在企业级 AI 迈向深度应用的关键节点,一个困扰开发者和企业的“不可能三角”浮出水面:模型既要足够开放透明、又必须足够智能,同时还要兼顾极致效率。单一维度上的突破已不足以支撑下一代 AI 智能体(Agent)的崛起。
近日,NVIDIA企业级生成式AI软件副总裁Kari Briski在一场分享中,详细阐述了NVIDIA 对开源生态的长期承诺,并重磅发布了其面向数字化智能体 AI 的开放模型家族——Nemotron 3。NVIDIA 宣称,Nemotron 3 的核心使命,正是要打破上述“不可能三角”,为开发者提供一个在效率、智能和开放性上都达到顶尖水平的基础。
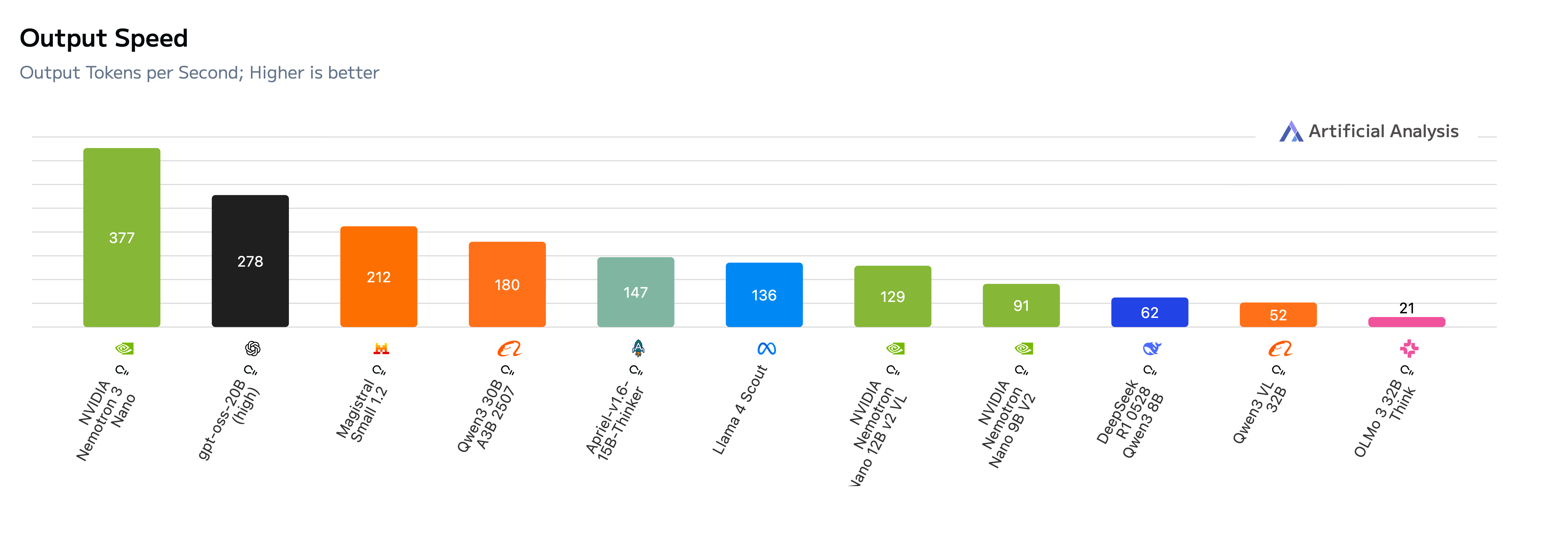
不同模型推理输出速度(tokens/s)对比,数值越高代表推理吞吐能力越强。
企业AI落地的三大趋势与挑战
在NVIDIA看来,当前企业级 AI 落地面临的第一个现实是:单一模型已经不够用了。真正能跑在生产环境中的 AI 应用,往往由多个模型协同组成,不同规模、不同模态的模型各司其职,再通过调度器或路由器把请求分发到最合适的模型上。一部分复杂问题需要调用专有的前沿模型,一部分高频、明确的任务则更适合交给体量更小、响应更快的专家模型。这种“模型系统化”的趋势,使得企业对模型的关注点从“最强能力”转向“整体效率、稳定性与可控性”。
与此同时,AI 在辅助专家工作时也逐渐触及瓶颈:要想真正走完“最后一公里”,模型必须深度贴合具体行业和专业场景,把私有数据和专家知识训练进模型之中,这对数据透明度、可再训练能力提出了更高要求。
另一个正在被反复提及的变化,是所谓“第三条 Scaling Law”开始显现影响。除了预训练和后训练之外,越来越多的智能提升来自推理阶段本身,也就是通过更长时间的思考、更复杂的推理链路来换取更高质量的答案。这种“推理时计算”的趋势在 Agent 场景中尤为明显,但其直接代价是 token 使用量和推理成本的快速上升。当多个智能体并行协作、反复调用工具时,成本曲线很容易失控。因此,企业真正需要的不是无限拉长的思维链,而是能够在保持甚至提升准确性的同时,用更少 token、更低延迟完成推理的高效率架构。
正是在这样的背景下,开源模型的重要性被重新放大。从 2024 年 Llama 3 推动 RAG 应用爆发,到 2025 年初以 DeepSeek 为代表的开放推理模型引发 Agent 化浪潮,越来越多的企业和开发者开始在开源模型和开源工具之上构建应用。LangChain 等框架的高速普及,以及 Hugging Face 上庞大的模型生态,都在说明一个事实:对大多数企业而言,开源已经不是“是否采用”的问题,而是“如何用好”的问题。
NVIDIA 坚信开源是 AI 创新的基础,并以实际行动成为开源社区的核心贡献者。仅在 2025 年,NVIDIA 就贡献了650个开源模型和250个开源数据集。在NVIDIA看来,开源并不是与商业对立的选择,而是推动生态加速的底座。开源所带来的并不仅是成本优势,更重要的是互操作性、透明度和创新扩散速度,这些恰恰是复杂系统走向规模化所不可或缺的基础。
Nemotron 3用“混合架构+MoE+百万token上下文”,解决不可能三角
Nemotron系列正是NVIDIA面向数字化智能体AI的推理模型家族。自2019年发布 Megatron开始,NVIDIA就持续在过去六年持续分享架构与优化经验,并在 Nemotron 1、Nemotron 2 的基础上,于本周二宣布正式发布 Nemotron 3开源推理模型。
NVIDIA强调,Nemotron的定位不只是“一个模型”,而是要成为企业可依赖的开源推理底座。
Kari Briski指出,Nemotron 是一个开放的推理生态,除了模型本身,还包括与内部一致的训练与推理框架库、公开的研究方法以及底层数据集。这种开放并不是停留在接口层,而是尽可能让开发者理解模型是如何被训练出来的、使用了哪些数据、在什么假设下形成能力边界,从而能够评估风险、进行域内再训练,并在此基础上构建可被信任的应用。对企业来说,这种“可审计的开源”比单纯追求模型性能更具现实意义。
作为这一体系的最新一代,Nemotron 3 的目标非常明确:不再让开发者在效率、开放性和智能之间做痛苦取舍。NVIDIA 将当前开源模型的主要矛盾概括为三条轴线——token 成本与吞吐等效率指标、代码和数据是否可信的开放程度,以及模型在真实任务中的推理能力。多数模型往往只能在其中两项表现出色,而 Nemotron 3 试图通过系统级设计,把这三条轴线同时拉高。
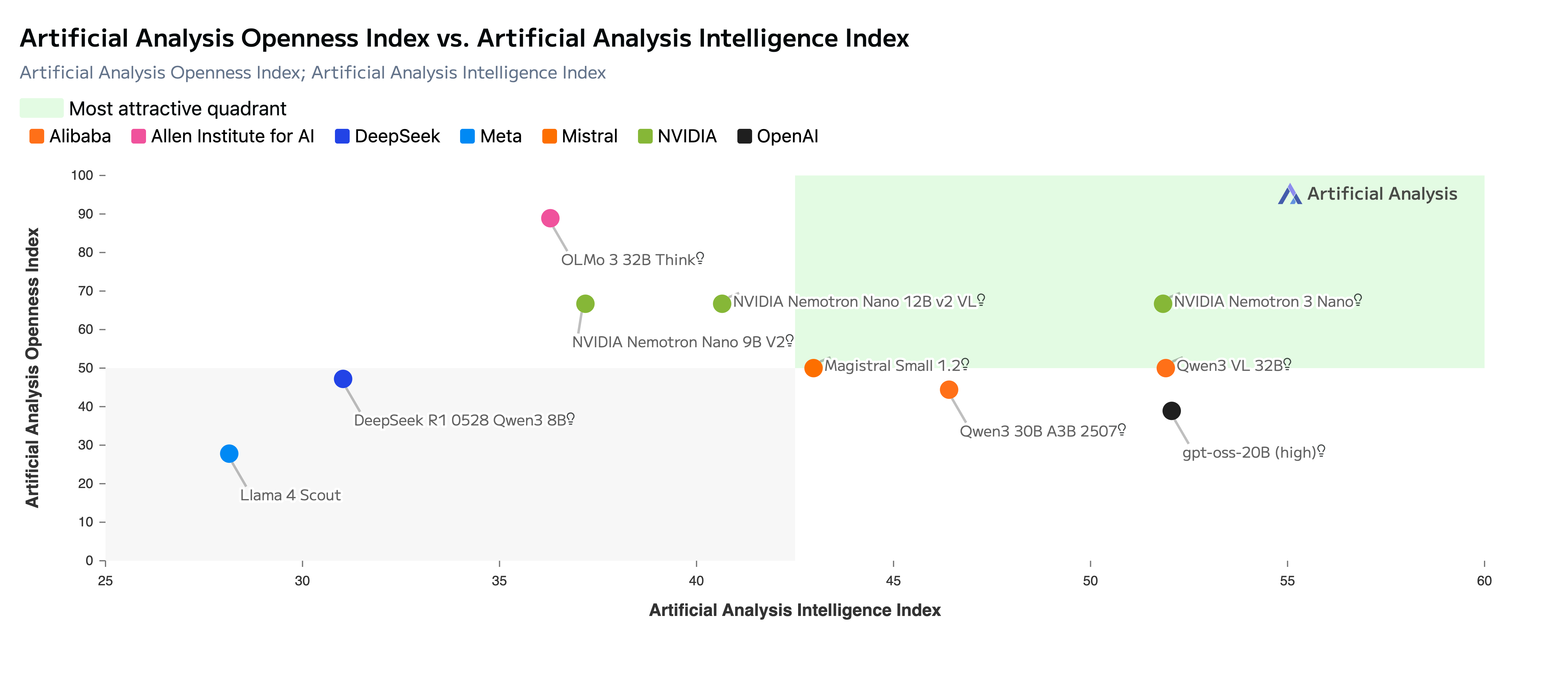
Artificial Analysis 对主流大模型在“智能指数(横轴)”与“开放性指数(纵轴)”上的综合评估结果。右上角象限代表同时具备较强推理能力与较高开放程度的模型区间。
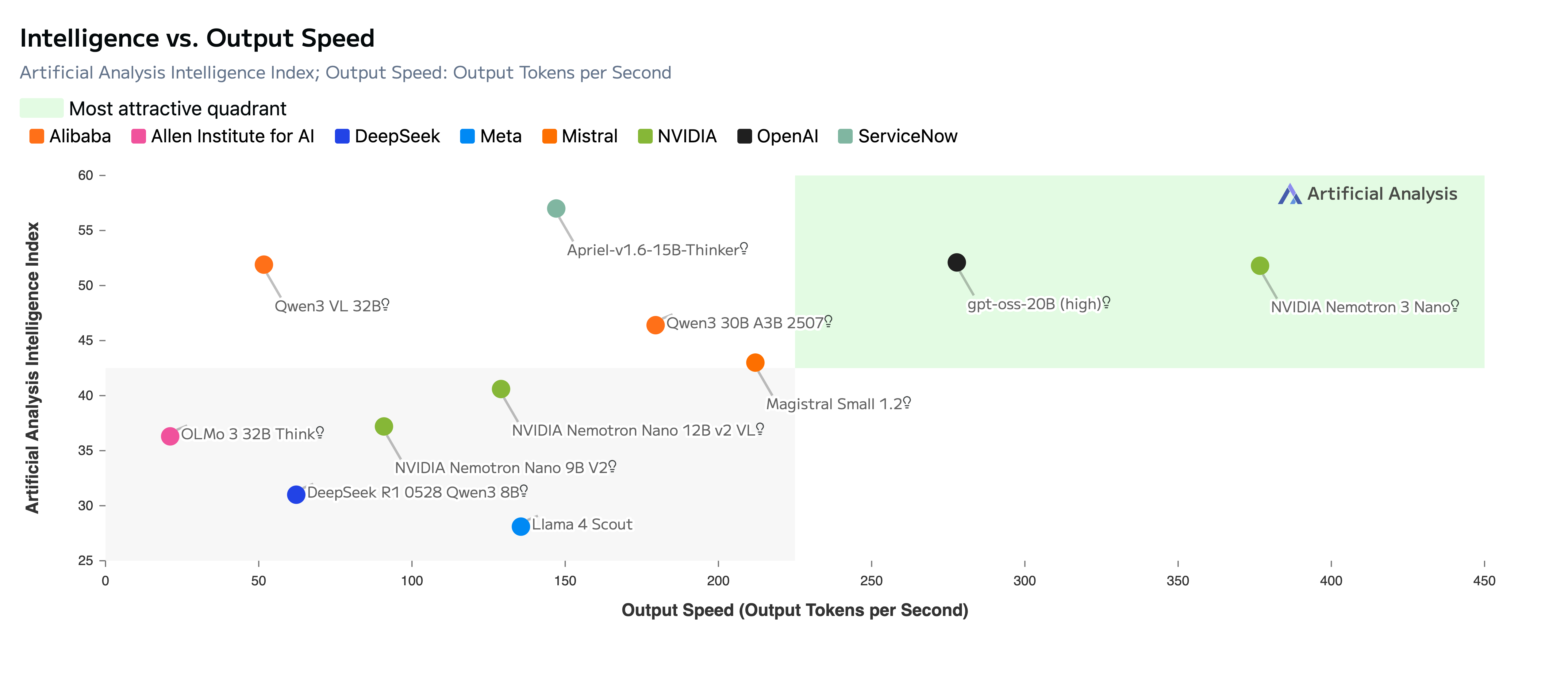
在Agent应用逐渐走向规模化的背景下,模型是否能够在保持推理质量的同时实现高吞吐,正在成为影响系统成本、并发能力与工程可行性的关键因素。右上角象限被视为“高智能 × 高效率”的最优区间。
为此,Nemotron 3 采用了混合 Mamba-Transformer 架构,并进一步引入 latent MoE(潜变量混合专家)机制,在降低注意力计算与内存占用的同时提升推理效率,使得在同等硬件条件下能够承载更多专家模型和更高并发。
在能力与形态上,Nemotron 3 的核心卖点是“混合专家架构 + 100 万 token 上下文长度”,用以支撑复杂多文档、长时任务中的高吞吐 Agent 系统。其家族包含三种规模的模型,试图在准确性、性能与算力之间取得不同平衡:Nemotron 3 Nano 总参数约 300 亿,但仅 30 亿参数处于激活状态,以高效率面向智能体任务;Nemotron 3 Super 约 1000 亿参数、激活参数约 100 亿,面向多智能体应用与更高准确性;Nemotron 3 Ultra 约 5000 亿参数,定位为大型推理引擎,通过混合 Mamba + MoE 架构在追求最高准确性的同时控制效率。
在训练与对齐层面,Nemotron 3同样强调“工程化可用性”。NVIDIA披露,其通过多环境强化学习训练,使模型在智能指标上相比前代获得显著提升,目标并不是生成更冗长的推理过程,而是更清晰地遵循指令、更快到达正确答案。
与模型同步发布的,还有一整套“可复现资产包”:约 3 万亿 token 的高质量预训练数据、约 1800 万条后训练样本,以及 Nemo Gym(被描述为首个开源、完整的强化学习环境)与 10 个 gym 训练环境,并将通过技术报告与研究论文公开架构设计与训练配方。NVIDIA 的意图非常明确:把 Nemotron 3 做成一个“模型 + 数据 + 工具 + 方法”的开源工程体系,而不是一次性权重投放。
从应用生态来看,Nemotron 的影响并不局限于“谁在用这套模型”。NVIDIA 特别强调,生态中的参与者可以以多种方式吸收这套开源成果:模型构建者可以复用其架构研究,主权 AI 项目可以基于其推理数据训练本地语言模型,安全厂商和企业软件公司可以用它来构建领域专用的智能体,而 AI 原生公司则可以将其纳入多模型路由系统中,按任务动态选择最优模型。在这一过程中,不同企业和平台彼此交织运行在云服务商、私有云和算力提供方之上,形成一个高度互联的 AI 产业网络。
在商业层面,NVIDIA 对“开源是否与自身平台战略冲突”的回应也颇具代表性。其核心观点是,开源并不等于放弃商业价值,而是通过提升开发者参与度和生态协作效率,反向巩固平台地位。就像软件库需要开放才能被广泛采用一样,当大模型被视为未来的软件开发平台,透明、可检查、可复现反而成为进入企业生产环境的前提。CUDA 体系本身也并非全然封闭,其大量 CUDA-X 库同样是开源的,是否开放取决于推动平台演进所需的参与深度。
结语
从这次披露的信息看,NVIDIA的Nemotron 3并不试图在“谁是最强前沿模型”上与专有巨头硬碰硬,而是把赌注押在另一条路径:以开源方式提供可规模化的推理模型体系,把Agent推向工业化。
当 AI 从单点能力升级为系统能力,真正稀缺的已经不只是更大的模型,而是能够长期依赖、可被治理、并在规模化协作中保持成本可控的推理基础设施。Nemotron 3 正是 NVIDIA 在这一方向上的一次集中下注,其成效如何,或许将直接影响企业级 Agent 生态下一阶段的演进速度。
近日,NVIDIA企业级生成式AI软件副总裁Kari Briski在一场分享中,详细阐述了NVIDIA 对开源生态的长期承诺,并重磅发布了其面向数字化智能体 AI 的开放模型家族——Nemotron 3。NVIDIA 宣称,Nemotron 3 的核心使命,正是要打破上述“不可能三角”,为开发者提供一个在效率、智能和开放性上都达到顶尖水平的基础。
不同模型推理输出速度(tokens/s)对比,数值越高代表推理吞吐能力越强。
企业AI落地的三大趋势与挑战
在NVIDIA看来,当前企业级 AI 落地面临的第一个现实是:单一模型已经不够用了。真正能跑在生产环境中的 AI 应用,往往由多个模型协同组成,不同规模、不同模态的模型各司其职,再通过调度器或路由器把请求分发到最合适的模型上。一部分复杂问题需要调用专有的前沿模型,一部分高频、明确的任务则更适合交给体量更小、响应更快的专家模型。这种“模型系统化”的趋势,使得企业对模型的关注点从“最强能力”转向“整体效率、稳定性与可控性”。
与此同时,AI 在辅助专家工作时也逐渐触及瓶颈:要想真正走完“最后一公里”,模型必须深度贴合具体行业和专业场景,把私有数据和专家知识训练进模型之中,这对数据透明度、可再训练能力提出了更高要求。
另一个正在被反复提及的变化,是所谓“第三条 Scaling Law”开始显现影响。除了预训练和后训练之外,越来越多的智能提升来自推理阶段本身,也就是通过更长时间的思考、更复杂的推理链路来换取更高质量的答案。这种“推理时计算”的趋势在 Agent 场景中尤为明显,但其直接代价是 token 使用量和推理成本的快速上升。当多个智能体并行协作、反复调用工具时,成本曲线很容易失控。因此,企业真正需要的不是无限拉长的思维链,而是能够在保持甚至提升准确性的同时,用更少 token、更低延迟完成推理的高效率架构。
正是在这样的背景下,开源模型的重要性被重新放大。从 2024 年 Llama 3 推动 RAG 应用爆发,到 2025 年初以 DeepSeek 为代表的开放推理模型引发 Agent 化浪潮,越来越多的企业和开发者开始在开源模型和开源工具之上构建应用。LangChain 等框架的高速普及,以及 Hugging Face 上庞大的模型生态,都在说明一个事实:对大多数企业而言,开源已经不是“是否采用”的问题,而是“如何用好”的问题。
NVIDIA 坚信开源是 AI 创新的基础,并以实际行动成为开源社区的核心贡献者。仅在 2025 年,NVIDIA 就贡献了650个开源模型和250个开源数据集。在NVIDIA看来,开源并不是与商业对立的选择,而是推动生态加速的底座。开源所带来的并不仅是成本优势,更重要的是互操作性、透明度和创新扩散速度,这些恰恰是复杂系统走向规模化所不可或缺的基础。
Nemotron 3用“混合架构+MoE+百万token上下文”,解决不可能三角
Nemotron系列正是NVIDIA面向数字化智能体AI的推理模型家族。自2019年发布 Megatron开始,NVIDIA就持续在过去六年持续分享架构与优化经验,并在 Nemotron 1、Nemotron 2 的基础上,于本周二宣布正式发布 Nemotron 3开源推理模型。
NVIDIA强调,Nemotron的定位不只是“一个模型”,而是要成为企业可依赖的开源推理底座。
Kari Briski指出,Nemotron 是一个开放的推理生态,除了模型本身,还包括与内部一致的训练与推理框架库、公开的研究方法以及底层数据集。这种开放并不是停留在接口层,而是尽可能让开发者理解模型是如何被训练出来的、使用了哪些数据、在什么假设下形成能力边界,从而能够评估风险、进行域内再训练,并在此基础上构建可被信任的应用。对企业来说,这种“可审计的开源”比单纯追求模型性能更具现实意义。
作为这一体系的最新一代,Nemotron 3 的目标非常明确:不再让开发者在效率、开放性和智能之间做痛苦取舍。NVIDIA 将当前开源模型的主要矛盾概括为三条轴线——token 成本与吞吐等效率指标、代码和数据是否可信的开放程度,以及模型在真实任务中的推理能力。多数模型往往只能在其中两项表现出色,而 Nemotron 3 试图通过系统级设计,把这三条轴线同时拉高。
Artificial Analysis 对主流大模型在“智能指数(横轴)”与“开放性指数(纵轴)”上的综合评估结果。右上角象限代表同时具备较强推理能力与较高开放程度的模型区间。
在Agent应用逐渐走向规模化的背景下,模型是否能够在保持推理质量的同时实现高吞吐,正在成为影响系统成本、并发能力与工程可行性的关键因素。右上角象限被视为“高智能 × 高效率”的最优区间。
为此,Nemotron 3 采用了混合 Mamba-Transformer 架构,并进一步引入 latent MoE(潜变量混合专家)机制,在降低注意力计算与内存占用的同时提升推理效率,使得在同等硬件条件下能够承载更多专家模型和更高并发。
在能力与形态上,Nemotron 3 的核心卖点是“混合专家架构 + 100 万 token 上下文长度”,用以支撑复杂多文档、长时任务中的高吞吐 Agent 系统。其家族包含三种规模的模型,试图在准确性、性能与算力之间取得不同平衡:Nemotron 3 Nano 总参数约 300 亿,但仅 30 亿参数处于激活状态,以高效率面向智能体任务;Nemotron 3 Super 约 1000 亿参数、激活参数约 100 亿,面向多智能体应用与更高准确性;Nemotron 3 Ultra 约 5000 亿参数,定位为大型推理引擎,通过混合 Mamba + MoE 架构在追求最高准确性的同时控制效率。
在训练与对齐层面,Nemotron 3同样强调“工程化可用性”。NVIDIA披露,其通过多环境强化学习训练,使模型在智能指标上相比前代获得显著提升,目标并不是生成更冗长的推理过程,而是更清晰地遵循指令、更快到达正确答案。
与模型同步发布的,还有一整套“可复现资产包”:约 3 万亿 token 的高质量预训练数据、约 1800 万条后训练样本,以及 Nemo Gym(被描述为首个开源、完整的强化学习环境)与 10 个 gym 训练环境,并将通过技术报告与研究论文公开架构设计与训练配方。NVIDIA 的意图非常明确:把 Nemotron 3 做成一个“模型 + 数据 + 工具 + 方法”的开源工程体系,而不是一次性权重投放。
从应用生态来看,Nemotron 的影响并不局限于“谁在用这套模型”。NVIDIA 特别强调,生态中的参与者可以以多种方式吸收这套开源成果:模型构建者可以复用其架构研究,主权 AI 项目可以基于其推理数据训练本地语言模型,安全厂商和企业软件公司可以用它来构建领域专用的智能体,而 AI 原生公司则可以将其纳入多模型路由系统中,按任务动态选择最优模型。在这一过程中,不同企业和平台彼此交织运行在云服务商、私有云和算力提供方之上,形成一个高度互联的 AI 产业网络。
在商业层面,NVIDIA 对“开源是否与自身平台战略冲突”的回应也颇具代表性。其核心观点是,开源并不等于放弃商业价值,而是通过提升开发者参与度和生态协作效率,反向巩固平台地位。就像软件库需要开放才能被广泛采用一样,当大模型被视为未来的软件开发平台,透明、可检查、可复现反而成为进入企业生产环境的前提。CUDA 体系本身也并非全然封闭,其大量 CUDA-X 库同样是开源的,是否开放取决于推动平台演进所需的参与深度。
结语
从这次披露的信息看,NVIDIA的Nemotron 3并不试图在“谁是最强前沿模型”上与专有巨头硬碰硬,而是把赌注押在另一条路径:以开源方式提供可规模化的推理模型体系,把Agent推向工业化。
当 AI 从单点能力升级为系统能力,真正稀缺的已经不只是更大的模型,而是能够长期依赖、可被治理、并在规模化协作中保持成本可控的推理基础设施。Nemotron 3 正是 NVIDIA 在这一方向上的一次集中下注,其成效如何,或许将直接影响企业级 Agent 生态下一阶段的演进速度。
责任编辑:duqin
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号