2026拐点已至:英特尔Panther Lake定义什么是“全能笔记本”
2026-03-13
19:04:09
来源: 杜芹
点击
3月12日,在上海黄浦江畔的春光中,英特尔副总裁高嵩将 2026 年定义为计算产业的“重要转折点”。伴随着代号 Panther Lake 的第三代酷睿 Ultra 处理器正式亮相,一场关于性能、续航与本地 AI 的革命正在中国这一全球最具活力的试验场中迅速引爆。
地基之战:Intel 18A 开启埃米时代
“工欲善其事,必先利其器。”在高嵩看来,Panther Lake的底气源于其坚实的制程地基——Intel 18A。这是半导体行业首次真正跨入“埃米时代”的里程碑。支撑这一跨越的,是两项颠覆性的底层逻辑创新:RibbonFET与PowerVia。

自2012年英特尔推出FinFET架构以来,晶体管架构长期未有本质质变。而RibbonFET(全环绕栅极晶体管)的出现,标志着一场真正的技术革命。不同于以往的两面或三面控制,RibbonFET实现了从四个维度对带状电流通道的完全包裹。这种精度带来的直接好处是:无论高低电压,晶体管的响应速度都大幅提升。而且Ribbon的宽度不再固定,设计者可根据能效需求灵活调整,且支持纵向堆叠。这意味着在相同的芯片面积下,可以容纳更多的晶体管,实现更高的性能密度。
如果说RibbonFET是在微观层面优化了开关,那么PowerVia(背面供电技术)则是在宏观架构上解决了一个困扰行业数十年的难题:供电与信号线路的“争道”矛盾。
在传统芯片设计中,供电与信号电路如同拥挤在晶体管上层的“孪生兄弟”,随着晶体管愈发密集,布线冲突与电压损耗愈发严重。英特尔通过PowerVia技术,巧妙地将供电电路搬迁至晶圆背面,实现了空间上的物理隔离。这样一来,背面专门承担供电任务,有助于降低电压损耗、提升供电效率;而正面则可以专注于信号传输,释放更多布线空间,改善信号质量与传输效率。
两项技术叠加,构成了 Intel 18A 最核心的竞争力。高嵩表示,正是通过 RibbonFET 与 PowerVia 的结合,英特尔在相较上一代工艺的基础上,实现了超过 15% 的每瓦性能提升,以及超过 30% 的芯片密度提升。这也被他称为“埃米时代的起点”。
“制程技术是地基,平台架构是蓝图。”高嵩强调。当行业进入非线性变革期,机遇只留给有准备的人。Panther Lake正是这种制程利器与领先架构相辅相成的产物,它不仅定义了埃米时代的起点,也为AI PC的算力爆发构建了广阔的“广厦千万间”。
不再妥协的轻薄本:Panther Lake的既要又要
在过去十多年里,轻薄本一直存在着一种“性能—体积—续航”的三角取舍。用户往往不得不在轻薄、性能和续航之间做出选择:轻薄意味着性能让步,而追求高性能又往往意味着更厚的机身、更高的功耗或更短的续航时间。
而今天,这种“取舍逻辑”正在被打破。冯大为指出,当下的用户已经不再愿意接受妥协。用户希望一台轻薄本既能够保持极致的机身设计,又能够提供强劲性能与长时间续航,同时还具备完整接口、优质质感以及丰富的 AI 能力。换句话说,轻薄本不再只是“够用即可”的移动办公设备,而是需要能够同时承担 工作、创作、娱乐、游戏以及 AI 应用的综合平台。
正是在这样的背景下,第三代酷睿 Ultra(Panther Lake)被英特尔定位为一次针对轻薄本能力边界的全面升级。
从技术架构来看,这一代平台在 CPU、GPU 与 AI 引擎三个维度都进行了系统性的提升。
1)CPU:双核齐发
在 CPU 核心层面,第三代酷睿 Ultra 引入了两种全新的核心架构:Cougar Cove 性能核与 Darkmont 能效核。
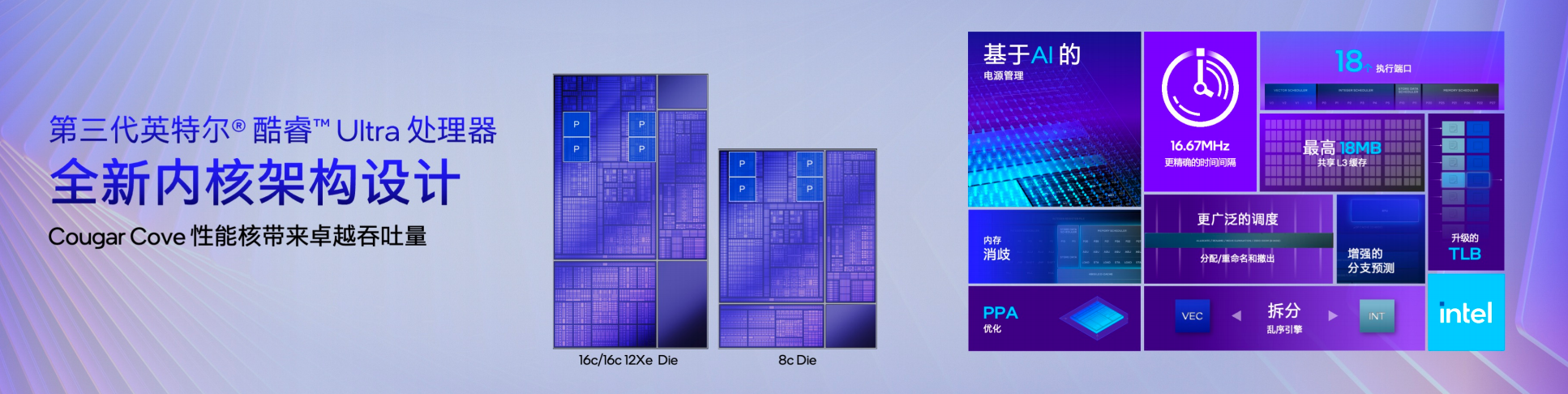
其中,Cougar Cove 性能核主要面向高负载应用场景。通过对前端执行引擎、缓存体系以及调度机制的全面优化,它能够提供更高的计算吞吐能力,为复杂计算、多线程任务以及高强度生产力应用提供强大的算力支撑。
而 Darkmont 能效核则承担更加综合的角色。一方面,其架构设计以低功耗为核心目标;另一方面,通过增加核心数量并优化执行路径,它能够显著增强处理器的并行处理能力。冯大为特别强调,得益于更高密度的核心布局和优化后的执行结构,Darkmont 在保持低功耗运行的同时,其计算能力已经接近过去一代性能核的水平。
除了核心架构的升级,这一代平台在低功耗设计上也进一步强化。英特尔将上一代 Lunar Lake 的低功耗设计经验引入到 Panther Lake 中,其中最关键的设计之一便是“低功耗岛(Low Power Island)”。
在该架构中,Darkmont 核心不仅被用于主计算模块中的 E 核,还被部署在低功耗域中的 LPE 核(Low Power Efficient Core)。当用户进行浏览网页、视频播放、在线会议等轻负载任务时,系统会优先由低功耗岛中的 LPE 核接管任务,从而让 P 核与 E 核保持更长时间的休眠状态,大幅降低整个平台功耗。
冯大为表示,在实际测试中,诸如网页浏览、办公应用、在线视频和远程协作等日常任务,都可以完全由低功耗岛承担,这也正是用户能够切实感受到续航提升的重要原因。
与此同时,更智能的线程调度机制也是这一代平台提升能效表现的关键。通过英特尔线程调度器与操作系统的协同配合,系统能够实时识别应用负载,并将任务分配到最合适的核心。例如,在游戏场景中,关键渲染线程会优先运行在 P 核上,而辅助任务则由 E 核处理;而在办公、会议或视频播放等轻负载场景下,系统则更多将任务分配给低功耗核心。
正是这种更加精细化的调度机制,使得 Panther Lake 能够在不同应用场景下实现性能与能效之间的动态平衡。
从实际测试数据来看,这一代平台的能效表现提升十分明显。在相同单线程性能条件下,处理器功耗最多可降低约 40%;而在相同功耗条件下,多线程性能相比上一代 Lunar Lake 提升超过60%。即便与Arrow Lake平台的285H处理器相比,也依然能够带来约 10%以上的性能提升。

在续航表现方面,官方数据显示,搭载第三代酷睿 Ultra 的笔记本在视频播放场景下最长可实现 27 小时续航;在日常办公生产力测试中续航最高可达 17 小时;即便是在长时间在线会议场景下,也能够保持 9 小时持续运行。
为了验证“27小时超长续航”并非实验室幻觉,英特尔在发布会现场同步开启了一场“续航大挑战”。从前一晚9点30分开始,三台不同工况的笔记本——分别执行本地视频播放、模拟办公场景以及复杂的龙虾任务脚本抓取。截至影视飓风创始人Tim分享时,三台机器已连续运行了17小时14分钟且依然电量充沛,其实测表现足以媲美顶级旗舰手机。谈及AI,Tim修正了他去年的预言:“我曾说AI生成将在两年内超越实拍,现在看,可能只需半年。”他强调,面对指数级增长的AI海啸,本地算力就是“可靠”的代名词。
“在信号归零的无人区,本地就等于可用。”Tim的话道出了无数开发者的心声。Panther Lake强大的端侧AI算力,让创作者无需盯着渲染条发呆,也不必依赖云端,在任何断连的角落,创意都能即刻落地。
2)核显革命:让轻薄本也能轻松玩3A游戏
另一项让现场关注度颇高的升级,则来自于全新的 Xe3 核显架构。冯大为表示,Xe3 在架构层面进行了多项重要升级,包括更大的缓存、对 DirectX 12 Ultimate 的支持、硬件级光线追踪能力的强化,以及基于 AI 的超分辨率与多帧生成技术。这也是目前市场上唯一支持多帧生成技术的核显产品。
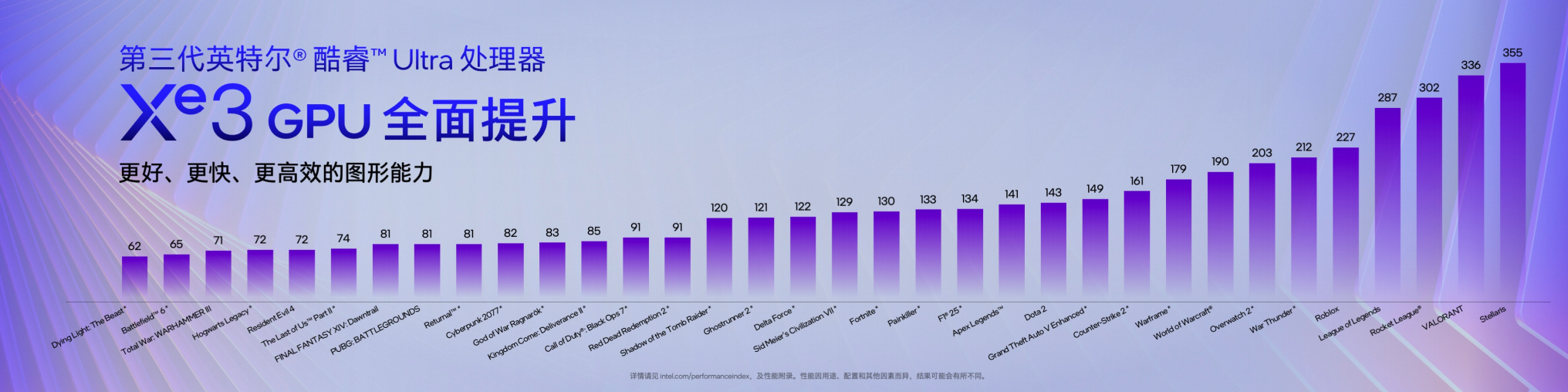
在 AI 加速方面,Xe3 还引入了 XMX AI 矩阵引擎,最高可提供 120 TOPS 算力,并结合共享内存架构,使其特别适合运行本地 AI 模型应用。在旗舰配置中,Xe3 核显最多可提供 12 个 Xe 核心。性能表现也因此实现明显跃升:与上一代 Lunar Lake平台相比,图形性能提升 超过50%,而在每瓦性能方面,相比 Arrow Lake 平台则提升超过40%。
“20年前,如果谈到游戏,几乎只有一个选择——台式机。”冯大为笑着回忆道,“后来我们把桌面级游戏体验带到了游戏本,而现在,Panther Lake 则让轻薄本也具备了运行大量 3A 游戏的能力。”在他看来,这一代产品真正实现了“全能型笔记本”的概念:既能够运行复杂工程软件和图形渲染任务,也能够满足游戏与娱乐需求,同时还保持全天候续航能力。
3)算力下沉:180 TOPS开启混合AI新纪元
当然,在 AI PC 成为行业新趋势的背景下,Panther Lake 的另一项关键升级则来自于 NPU 5 AI 推理引擎。这一代 NPU 的 AI 算力最高可达到 50 TOPS,全面满足微软 Copilot+ PC 的标准需求,并为开发者提供专用的高性能 AI 推理平台。相比 CPU 或 GPU,NPU 在执行 AI 推理任务时拥有更高能效比,因此特别适合长期运行的本地模型应用。随着 AI PC 生态不断成熟,越来越多应用需要模型在本地常驻运行。NPU 的引入不仅可以降低系统功耗,还能释放 CPU 与 GPU 资源,从而进一步提升多任务体验。

冯大为透露,自第一代酷睿 Ultra 处理器发布以来,英特尔已经向市场累计交付超过一亿台 AI PC。这些设备所汇聚的端侧AI总算力已达到 4 ZettaOps,相当于约 40 座大型数据中心的计算能力。
而在 Panther Lake 平台上,通过 CPU、GPU 与 NPU 构成的 XPU 异构架构,整个平台 AI 算力最高可达到 180 TOPS,进一步推动 AI 计算向端侧扩展。
在英特尔看来,未来 AI 应用并不会是“云或端”的选择题,而更可能是一种端云协同的混合计算模式。事实上,这样的应用已经开始在现实场景中出现。冯大为现场以剪映的一项 AI 视频编辑功能为例进行演示:通过本地 AI 算力,系统可以自动完成素材分析、文案生成和粗剪处理,大幅减少创作者的编辑时间。最关键的是,这一过程无需将视频素材上传云端,既节省了网络传输时间,也降低了对云端算力的依赖。
从碳基牛马到游戏大神:Panther Lake的AI实战与跨代体验
在摄影界,AI修图早已是生产力的基石。高宇现场展示了与像素蛋糕(PeraCake)的深度合作。通过Panther Lake的GPU加速,原本人工精修需15分钟的照片,现在仅需30秒。这意味着5分钟处理100张商业大片成为了摄影师在户外的标配工具。
针对AIGC中的提示词枯竭痛点,英特尔联合小云雀推出了基于千问34B模型的本地端侧方案。通过“人机协作”,模型能无延迟地实时续写提示词,让曾经的抽卡玄学变成了精准的创意掌控。
更有趣的尝试来自于人机交互。内置于NPU运行的“樱桃AI智能语音助手”,以1.5B的小参数模型实现了对300多条系统指令及第三方应用的深度操控。最令现场观众印象深刻的是其隐藏的“健康监测”功能:无需额外穿戴设备,仅通过摄像头与AI算法,即可实时监测“职场牛马”的心跳、血压与血氧趋势。
当话题转到尾标为8的酷睿 Ultra X系列时,高宇提出了一个挑衅性的问题:轻薄本真的能“全能”吗?答案藏在Xe3架构与XeSS 3.0技术中:XeSS 3.0首次实现了多帧生成(MFG 4X),通过AI连续生成三帧,将《赛博朋克2077》等3A大作的帧率从40多帧直接拉升至150帧;在热门射击游戏《三角洲行动》的实测中,Panther Lake竟然在轻薄本形态下跑出了300帧的惊人成绩,彻底模糊了全能本与游戏本的边界。

发布会现场迎来了一位特殊的嘉宾——曾因“两枪爆头世界冠军”而走红的60岁游戏主播六六的娟姨。当这位“大神”在轻薄本上完成“嘎嘎乱杀”后,她感叹道:“没想到笔记本也能玩出台式机的感受,我老太婆也享受到了科技进步的福利。”这一幕深刻诠释了高宇的观点:玩好电竞的不一定是年轻人,跑得动游戏的也不一定是游戏本。
在AI性能的最前沿,Panther Lake展示了其对千问3.5家族的极致适配。得益于英特尔可调显存技术,仅需32GB内存的主流笔记本,即可本地部署35B规模的大模型。高宇指出,35B模型凭借MOE架构,在语言理解、代码生成甚至Agentic能力上已逼近甚至超越了某些百亿级模型。Panther Lake不仅是计算平台,更是移动端的AI实验室。
针对时下最火热的“龙虾(AI Agentic应用)”场景,高宇直击重度用户的痛点:Token焦虑。一个复杂的Agentic任务链往往会消耗数百万甚至上亿的Token。通过现场演示,高宇展示了由本地35B模型驱动的“小龙虾”:四只“本地龙虾”各司其职,从文件自动聚类、日报自动生成,到跨模态的相册搜索。强的一只龙虾甚至根据模糊指令,自动编写JavaScript代码,实时抓取开源气象数据并生成了一个动态看板。高宇坦言,虽然最强的模型仍在云端,但本地模型在时延、隐私和成本上具有无可比拟的优势。Panther Lake开启的,正是这种“云上云下协同”的混合AI新常态。
发布会最令人惊艳的“彩蛋”莫过于一只3D打印的小豹子。这并非预制素材,而是全流程由Panther Lake的12Xe本地算力实时生成:使用Z-image模型,20秒生成具有东方美感的2D高清图;调动混元3D模型,仅耗时80秒便完成了从2D到3D纹理资产的转化;配合创想三维(Creality)的深度适配,数字资产直接驱动3D打印机输出。未来的创意世界只有两个词:人类动脑,AI动手。”高宇的话掷地有声。从提示词到实物模型,Panther Lake重塑了从理想到现实的链路。
PC阵营全面跟进,共绘 Panther Lake 的下半场蓝图
“独木难成林,风雨同舟行。”高嵩强调,英特尔的突破离不开生态的力量。随着联想集团副总裁李伟昌等老友的登台,联想与华硕等厂商首批AIPC产品的亮相,标志着这一场“不妥协”的技术革命已正式从发布会走入消费者的生活。
联想集团副总裁李伟昌认为,Panther Lake 是迄今为止移动端最完美的芯片,它为联想天禧 AI 从“聊天助手”进化到“自动化引擎”提供了核心动力。2026 年的 AIPC 不再只是等待指令,而是能主动规划、执行并交付结果。这背后依托的是 Panther Lake 高达 180 TOPS 的算力支撑,实现了“本地优先、全流程接管、主动服务”。
联想同步揭晓了三款重磅产品。其中,小新 Pro 14 GT 凭借 Panther Lake 的高能效与联想的调优,本地视频播放续航达到了惊人的 34.8 小时,堪称轻薄本的续航之王;而 Yoga Air 14 Ultra 更是全场瞩目的焦点——它在不到 975 克 的机身内,塞进了顶级 Ultra X9 388H 芯片,刷新了轻薄旗舰的认知上限。
华硕也已将 Panther Lake 完美封装入多元的产品矩阵中。作为创新的代表,灵耀 14 双屏 2026该机型搭载了 9600MT/S 超高频内存,屏占比高达 93%。在 Panther Lake 强劲图形性能的支持下,其本地 AI 模型处理能力提升了 82%,配合独家的小硕知道智能助手,让双屏协作从好用进化到智慧。
华硕无畏 Pro 系列通过“冰封 Pro 散热架构”,在轻薄机身内稳稳落地了 85 瓦 的强悍性能释放,彻底解决了全能本在散热与续航间的长期博弈,精准击中了职场新人与学生群体的痛点。
此外还有小米、宏碁、荣耀、惠普等一众合作伙伴的创新结晶,尤其是预热了即将上市的小米 Mibook 14。
结语
高嵩引用诗句“满眼生机转化钧,天工人巧日争新”为分享会收官。2026 年,Panther Lake 以 180 TOPS 算力、27 小时+ 续航和不妥协的图形性能,正式拉开了 AIPC 行业新纪元的序幕。这不只是一颗芯片的发布,更是一个时代的转型点。
地基之战:Intel 18A 开启埃米时代
“工欲善其事,必先利其器。”在高嵩看来,Panther Lake的底气源于其坚实的制程地基——Intel 18A。这是半导体行业首次真正跨入“埃米时代”的里程碑。支撑这一跨越的,是两项颠覆性的底层逻辑创新:RibbonFET与PowerVia。
自2012年英特尔推出FinFET架构以来,晶体管架构长期未有本质质变。而RibbonFET(全环绕栅极晶体管)的出现,标志着一场真正的技术革命。不同于以往的两面或三面控制,RibbonFET实现了从四个维度对带状电流通道的完全包裹。这种精度带来的直接好处是:无论高低电压,晶体管的响应速度都大幅提升。而且Ribbon的宽度不再固定,设计者可根据能效需求灵活调整,且支持纵向堆叠。这意味着在相同的芯片面积下,可以容纳更多的晶体管,实现更高的性能密度。
如果说RibbonFET是在微观层面优化了开关,那么PowerVia(背面供电技术)则是在宏观架构上解决了一个困扰行业数十年的难题:供电与信号线路的“争道”矛盾。
在传统芯片设计中,供电与信号电路如同拥挤在晶体管上层的“孪生兄弟”,随着晶体管愈发密集,布线冲突与电压损耗愈发严重。英特尔通过PowerVia技术,巧妙地将供电电路搬迁至晶圆背面,实现了空间上的物理隔离。这样一来,背面专门承担供电任务,有助于降低电压损耗、提升供电效率;而正面则可以专注于信号传输,释放更多布线空间,改善信号质量与传输效率。
两项技术叠加,构成了 Intel 18A 最核心的竞争力。高嵩表示,正是通过 RibbonFET 与 PowerVia 的结合,英特尔在相较上一代工艺的基础上,实现了超过 15% 的每瓦性能提升,以及超过 30% 的芯片密度提升。这也被他称为“埃米时代的起点”。
“制程技术是地基,平台架构是蓝图。”高嵩强调。当行业进入非线性变革期,机遇只留给有准备的人。Panther Lake正是这种制程利器与领先架构相辅相成的产物,它不仅定义了埃米时代的起点,也为AI PC的算力爆发构建了广阔的“广厦千万间”。
不再妥协的轻薄本:Panther Lake的既要又要
在过去十多年里,轻薄本一直存在着一种“性能—体积—续航”的三角取舍。用户往往不得不在轻薄、性能和续航之间做出选择:轻薄意味着性能让步,而追求高性能又往往意味着更厚的机身、更高的功耗或更短的续航时间。
而今天,这种“取舍逻辑”正在被打破。冯大为指出,当下的用户已经不再愿意接受妥协。用户希望一台轻薄本既能够保持极致的机身设计,又能够提供强劲性能与长时间续航,同时还具备完整接口、优质质感以及丰富的 AI 能力。换句话说,轻薄本不再只是“够用即可”的移动办公设备,而是需要能够同时承担 工作、创作、娱乐、游戏以及 AI 应用的综合平台。
正是在这样的背景下,第三代酷睿 Ultra(Panther Lake)被英特尔定位为一次针对轻薄本能力边界的全面升级。
从技术架构来看,这一代平台在 CPU、GPU 与 AI 引擎三个维度都进行了系统性的提升。
1)CPU:双核齐发
在 CPU 核心层面,第三代酷睿 Ultra 引入了两种全新的核心架构:Cougar Cove 性能核与 Darkmont 能效核。
其中,Cougar Cove 性能核主要面向高负载应用场景。通过对前端执行引擎、缓存体系以及调度机制的全面优化,它能够提供更高的计算吞吐能力,为复杂计算、多线程任务以及高强度生产力应用提供强大的算力支撑。
而 Darkmont 能效核则承担更加综合的角色。一方面,其架构设计以低功耗为核心目标;另一方面,通过增加核心数量并优化执行路径,它能够显著增强处理器的并行处理能力。冯大为特别强调,得益于更高密度的核心布局和优化后的执行结构,Darkmont 在保持低功耗运行的同时,其计算能力已经接近过去一代性能核的水平。
除了核心架构的升级,这一代平台在低功耗设计上也进一步强化。英特尔将上一代 Lunar Lake 的低功耗设计经验引入到 Panther Lake 中,其中最关键的设计之一便是“低功耗岛(Low Power Island)”。
在该架构中,Darkmont 核心不仅被用于主计算模块中的 E 核,还被部署在低功耗域中的 LPE 核(Low Power Efficient Core)。当用户进行浏览网页、视频播放、在线会议等轻负载任务时,系统会优先由低功耗岛中的 LPE 核接管任务,从而让 P 核与 E 核保持更长时间的休眠状态,大幅降低整个平台功耗。
冯大为表示,在实际测试中,诸如网页浏览、办公应用、在线视频和远程协作等日常任务,都可以完全由低功耗岛承担,这也正是用户能够切实感受到续航提升的重要原因。
与此同时,更智能的线程调度机制也是这一代平台提升能效表现的关键。通过英特尔线程调度器与操作系统的协同配合,系统能够实时识别应用负载,并将任务分配到最合适的核心。例如,在游戏场景中,关键渲染线程会优先运行在 P 核上,而辅助任务则由 E 核处理;而在办公、会议或视频播放等轻负载场景下,系统则更多将任务分配给低功耗核心。
正是这种更加精细化的调度机制,使得 Panther Lake 能够在不同应用场景下实现性能与能效之间的动态平衡。
从实际测试数据来看,这一代平台的能效表现提升十分明显。在相同单线程性能条件下,处理器功耗最多可降低约 40%;而在相同功耗条件下,多线程性能相比上一代 Lunar Lake 提升超过60%。即便与Arrow Lake平台的285H处理器相比,也依然能够带来约 10%以上的性能提升。
在续航表现方面,官方数据显示,搭载第三代酷睿 Ultra 的笔记本在视频播放场景下最长可实现 27 小时续航;在日常办公生产力测试中续航最高可达 17 小时;即便是在长时间在线会议场景下,也能够保持 9 小时持续运行。
为了验证“27小时超长续航”并非实验室幻觉,英特尔在发布会现场同步开启了一场“续航大挑战”。从前一晚9点30分开始,三台不同工况的笔记本——分别执行本地视频播放、模拟办公场景以及复杂的龙虾任务脚本抓取。截至影视飓风创始人Tim分享时,三台机器已连续运行了17小时14分钟且依然电量充沛,其实测表现足以媲美顶级旗舰手机。谈及AI,Tim修正了他去年的预言:“我曾说AI生成将在两年内超越实拍,现在看,可能只需半年。”他强调,面对指数级增长的AI海啸,本地算力就是“可靠”的代名词。
“在信号归零的无人区,本地就等于可用。”Tim的话道出了无数开发者的心声。Panther Lake强大的端侧AI算力,让创作者无需盯着渲染条发呆,也不必依赖云端,在任何断连的角落,创意都能即刻落地。
2)核显革命:让轻薄本也能轻松玩3A游戏
另一项让现场关注度颇高的升级,则来自于全新的 Xe3 核显架构。冯大为表示,Xe3 在架构层面进行了多项重要升级,包括更大的缓存、对 DirectX 12 Ultimate 的支持、硬件级光线追踪能力的强化,以及基于 AI 的超分辨率与多帧生成技术。这也是目前市场上唯一支持多帧生成技术的核显产品。
在 AI 加速方面,Xe3 还引入了 XMX AI 矩阵引擎,最高可提供 120 TOPS 算力,并结合共享内存架构,使其特别适合运行本地 AI 模型应用。在旗舰配置中,Xe3 核显最多可提供 12 个 Xe 核心。性能表现也因此实现明显跃升:与上一代 Lunar Lake平台相比,图形性能提升 超过50%,而在每瓦性能方面,相比 Arrow Lake 平台则提升超过40%。
“20年前,如果谈到游戏,几乎只有一个选择——台式机。”冯大为笑着回忆道,“后来我们把桌面级游戏体验带到了游戏本,而现在,Panther Lake 则让轻薄本也具备了运行大量 3A 游戏的能力。”在他看来,这一代产品真正实现了“全能型笔记本”的概念:既能够运行复杂工程软件和图形渲染任务,也能够满足游戏与娱乐需求,同时还保持全天候续航能力。
3)算力下沉:180 TOPS开启混合AI新纪元
当然,在 AI PC 成为行业新趋势的背景下,Panther Lake 的另一项关键升级则来自于 NPU 5 AI 推理引擎。这一代 NPU 的 AI 算力最高可达到 50 TOPS,全面满足微软 Copilot+ PC 的标准需求,并为开发者提供专用的高性能 AI 推理平台。相比 CPU 或 GPU,NPU 在执行 AI 推理任务时拥有更高能效比,因此特别适合长期运行的本地模型应用。随着 AI PC 生态不断成熟,越来越多应用需要模型在本地常驻运行。NPU 的引入不仅可以降低系统功耗,还能释放 CPU 与 GPU 资源,从而进一步提升多任务体验。
冯大为透露,自第一代酷睿 Ultra 处理器发布以来,英特尔已经向市场累计交付超过一亿台 AI PC。这些设备所汇聚的端侧AI总算力已达到 4 ZettaOps,相当于约 40 座大型数据中心的计算能力。
而在 Panther Lake 平台上,通过 CPU、GPU 与 NPU 构成的 XPU 异构架构,整个平台 AI 算力最高可达到 180 TOPS,进一步推动 AI 计算向端侧扩展。
在英特尔看来,未来 AI 应用并不会是“云或端”的选择题,而更可能是一种端云协同的混合计算模式。事实上,这样的应用已经开始在现实场景中出现。冯大为现场以剪映的一项 AI 视频编辑功能为例进行演示:通过本地 AI 算力,系统可以自动完成素材分析、文案生成和粗剪处理,大幅减少创作者的编辑时间。最关键的是,这一过程无需将视频素材上传云端,既节省了网络传输时间,也降低了对云端算力的依赖。
从碳基牛马到游戏大神:Panther Lake的AI实战与跨代体验
在摄影界,AI修图早已是生产力的基石。高宇现场展示了与像素蛋糕(PeraCake)的深度合作。通过Panther Lake的GPU加速,原本人工精修需15分钟的照片,现在仅需30秒。这意味着5分钟处理100张商业大片成为了摄影师在户外的标配工具。
针对AIGC中的提示词枯竭痛点,英特尔联合小云雀推出了基于千问34B模型的本地端侧方案。通过“人机协作”,模型能无延迟地实时续写提示词,让曾经的抽卡玄学变成了精准的创意掌控。
更有趣的尝试来自于人机交互。内置于NPU运行的“樱桃AI智能语音助手”,以1.5B的小参数模型实现了对300多条系统指令及第三方应用的深度操控。最令现场观众印象深刻的是其隐藏的“健康监测”功能:无需额外穿戴设备,仅通过摄像头与AI算法,即可实时监测“职场牛马”的心跳、血压与血氧趋势。
当话题转到尾标为8的酷睿 Ultra X系列时,高宇提出了一个挑衅性的问题:轻薄本真的能“全能”吗?答案藏在Xe3架构与XeSS 3.0技术中:XeSS 3.0首次实现了多帧生成(MFG 4X),通过AI连续生成三帧,将《赛博朋克2077》等3A大作的帧率从40多帧直接拉升至150帧;在热门射击游戏《三角洲行动》的实测中,Panther Lake竟然在轻薄本形态下跑出了300帧的惊人成绩,彻底模糊了全能本与游戏本的边界。
发布会现场迎来了一位特殊的嘉宾——曾因“两枪爆头世界冠军”而走红的60岁游戏主播六六的娟姨。当这位“大神”在轻薄本上完成“嘎嘎乱杀”后,她感叹道:“没想到笔记本也能玩出台式机的感受,我老太婆也享受到了科技进步的福利。”这一幕深刻诠释了高宇的观点:玩好电竞的不一定是年轻人,跑得动游戏的也不一定是游戏本。
在AI性能的最前沿,Panther Lake展示了其对千问3.5家族的极致适配。得益于英特尔可调显存技术,仅需32GB内存的主流笔记本,即可本地部署35B规模的大模型。高宇指出,35B模型凭借MOE架构,在语言理解、代码生成甚至Agentic能力上已逼近甚至超越了某些百亿级模型。Panther Lake不仅是计算平台,更是移动端的AI实验室。
针对时下最火热的“龙虾(AI Agentic应用)”场景,高宇直击重度用户的痛点:Token焦虑。一个复杂的Agentic任务链往往会消耗数百万甚至上亿的Token。通过现场演示,高宇展示了由本地35B模型驱动的“小龙虾”:四只“本地龙虾”各司其职,从文件自动聚类、日报自动生成,到跨模态的相册搜索。强的一只龙虾甚至根据模糊指令,自动编写JavaScript代码,实时抓取开源气象数据并生成了一个动态看板。高宇坦言,虽然最强的模型仍在云端,但本地模型在时延、隐私和成本上具有无可比拟的优势。Panther Lake开启的,正是这种“云上云下协同”的混合AI新常态。
发布会最令人惊艳的“彩蛋”莫过于一只3D打印的小豹子。这并非预制素材,而是全流程由Panther Lake的12Xe本地算力实时生成:使用Z-image模型,20秒生成具有东方美感的2D高清图;调动混元3D模型,仅耗时80秒便完成了从2D到3D纹理资产的转化;配合创想三维(Creality)的深度适配,数字资产直接驱动3D打印机输出。未来的创意世界只有两个词:人类动脑,AI动手。”高宇的话掷地有声。从提示词到实物模型,Panther Lake重塑了从理想到现实的链路。
PC阵营全面跟进,共绘 Panther Lake 的下半场蓝图
“独木难成林,风雨同舟行。”高嵩强调,英特尔的突破离不开生态的力量。随着联想集团副总裁李伟昌等老友的登台,联想与华硕等厂商首批AIPC产品的亮相,标志着这一场“不妥协”的技术革命已正式从发布会走入消费者的生活。
联想集团副总裁李伟昌认为,Panther Lake 是迄今为止移动端最完美的芯片,它为联想天禧 AI 从“聊天助手”进化到“自动化引擎”提供了核心动力。2026 年的 AIPC 不再只是等待指令,而是能主动规划、执行并交付结果。这背后依托的是 Panther Lake 高达 180 TOPS 的算力支撑,实现了“本地优先、全流程接管、主动服务”。
联想同步揭晓了三款重磅产品。其中,小新 Pro 14 GT 凭借 Panther Lake 的高能效与联想的调优,本地视频播放续航达到了惊人的 34.8 小时,堪称轻薄本的续航之王;而 Yoga Air 14 Ultra 更是全场瞩目的焦点——它在不到 975 克 的机身内,塞进了顶级 Ultra X9 388H 芯片,刷新了轻薄旗舰的认知上限。
华硕也已将 Panther Lake 完美封装入多元的产品矩阵中。作为创新的代表,灵耀 14 双屏 2026该机型搭载了 9600MT/S 超高频内存,屏占比高达 93%。在 Panther Lake 强劲图形性能的支持下,其本地 AI 模型处理能力提升了 82%,配合独家的小硕知道智能助手,让双屏协作从好用进化到智慧。
华硕无畏 Pro 系列通过“冰封 Pro 散热架构”,在轻薄机身内稳稳落地了 85 瓦 的强悍性能释放,彻底解决了全能本在散热与续航间的长期博弈,精准击中了职场新人与学生群体的痛点。
此外还有小米、宏碁、荣耀、惠普等一众合作伙伴的创新结晶,尤其是预热了即将上市的小米 Mibook 14。
结语
高嵩引用诗句“满眼生机转化钧,天工人巧日争新”为分享会收官。2026 年,Panther Lake 以 180 TOPS 算力、27 小时+ 续航和不妥协的图形性能,正式拉开了 AIPC 行业新纪元的序幕。这不只是一颗芯片的发布,更是一个时代的转型点。
责任编辑:duqin
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号