AI PC进入“Panther时代”:这次,英特尔押上了18A
2025-10-13
21:38:32
来源: 杜芹
点击
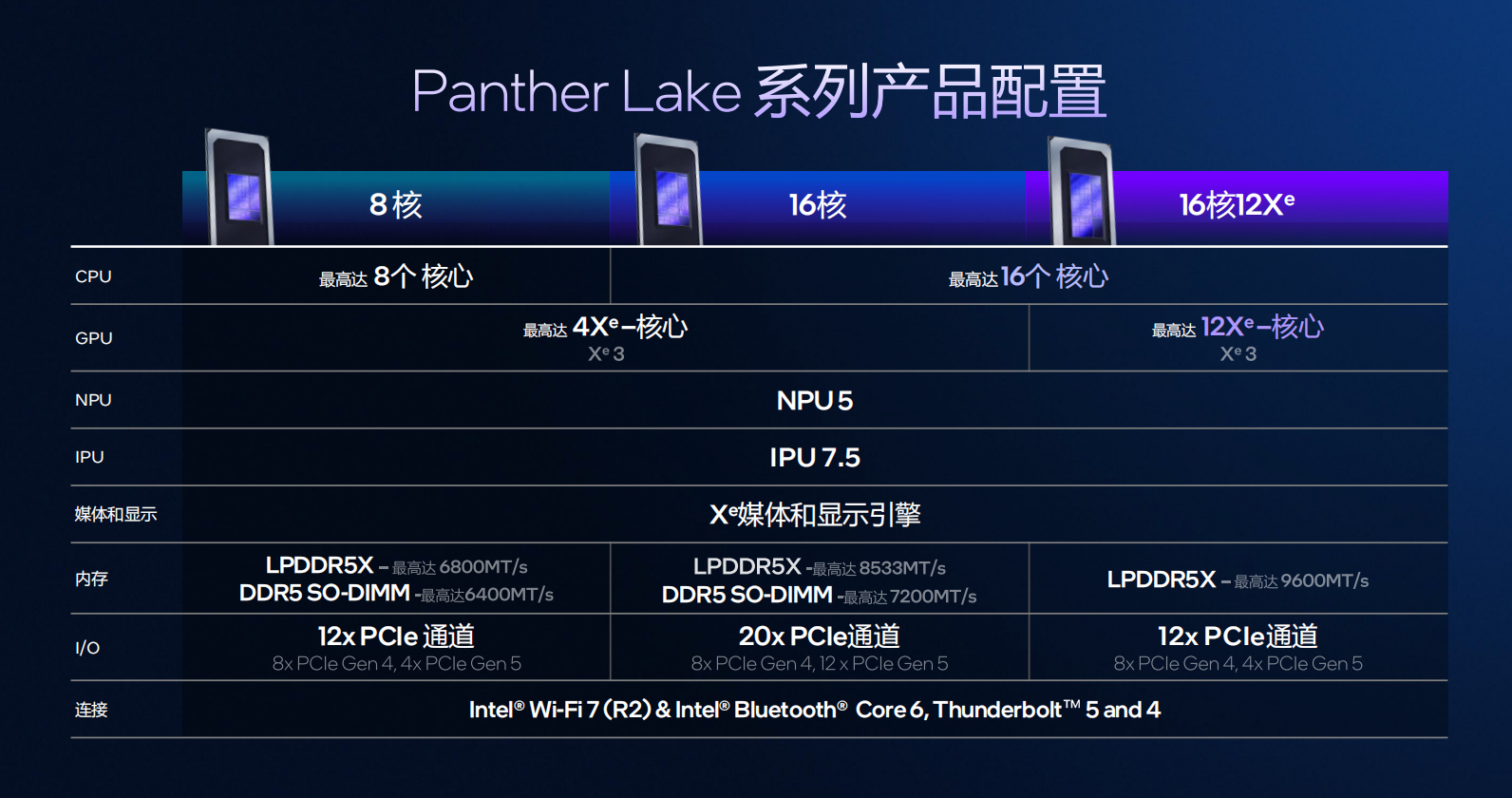
近日,英特尔重磅发布了新一代移动CPU Panther Lake。“它的发布是英特尔的重要里程碑。这款基于 Intel 18A制程打造的新平台,不仅融合了 RibbonFET 与 PowerVia 两项领先技术,为性能与能效提供坚实支撑,也为未来三代产品奠定了基础”。英特尔公司客户端计算事业部副总裁兼中国区总经理高嵩在近日的一次媒体沟通会上表示。Panther Lake延续Lunar Lake的高能效与Arrow Lake的高性能优势,并在CPU与GPU性能上均实现约50%的提升,最高配备16核CPU与12个Xe GPU核心。
那么,这款芯片的背后究竟有多少黑科技的加持?
Intel 18A + Foveros:工艺与封装的“双引擎”
英特尔技术专家指出,生成式AI的普及推动了从服务器到个人设备的算力需求激增,也对芯片制造提出了更高的复杂度与整合度要求。目前行业正面临四大挑战:
l 成本飙升:晶体管密度提升导致工艺难度与投入不断增加,良率控制更具挑战。
l 供电瓶颈:AI时代能效成为关键,从系统电力到晶体管级供电都需创新突破。
l 规模极限:单晶圆面积受限,传统单芯片方案难以兼顾性能与良率。
l 标准碎片化:接口、协议与测试标准不统一,限制了跨平台协同与规模化落地。
面对这多重挑战,英特尔正通过工艺与架构创新不断突破瓶颈,推动行业从 System on Chip (SoC) 向 System of Chip (SoCh) 演进,实现更高的规模化、灵活性与生态协同。
具体而言,英特尔正通过Intel 18A + RibbonFET + PowerVia + Foveros四大技术支柱,全面推动芯片制造进入 AI时代的系统级集成阶段。
Intel 18A制程:英特尔最先进的工艺节点,目前已在美国亚利桑那州Fab-52工厂全面启动量产。在同一时期,Intel 18A的良率大于等于之前的每一代的节点,预计2025年第四季度实现大规模稳定生产,支撑包括 Panther Lake(消费端)与 Clearwater Forest(服务器端)在内的新一代产品落地。
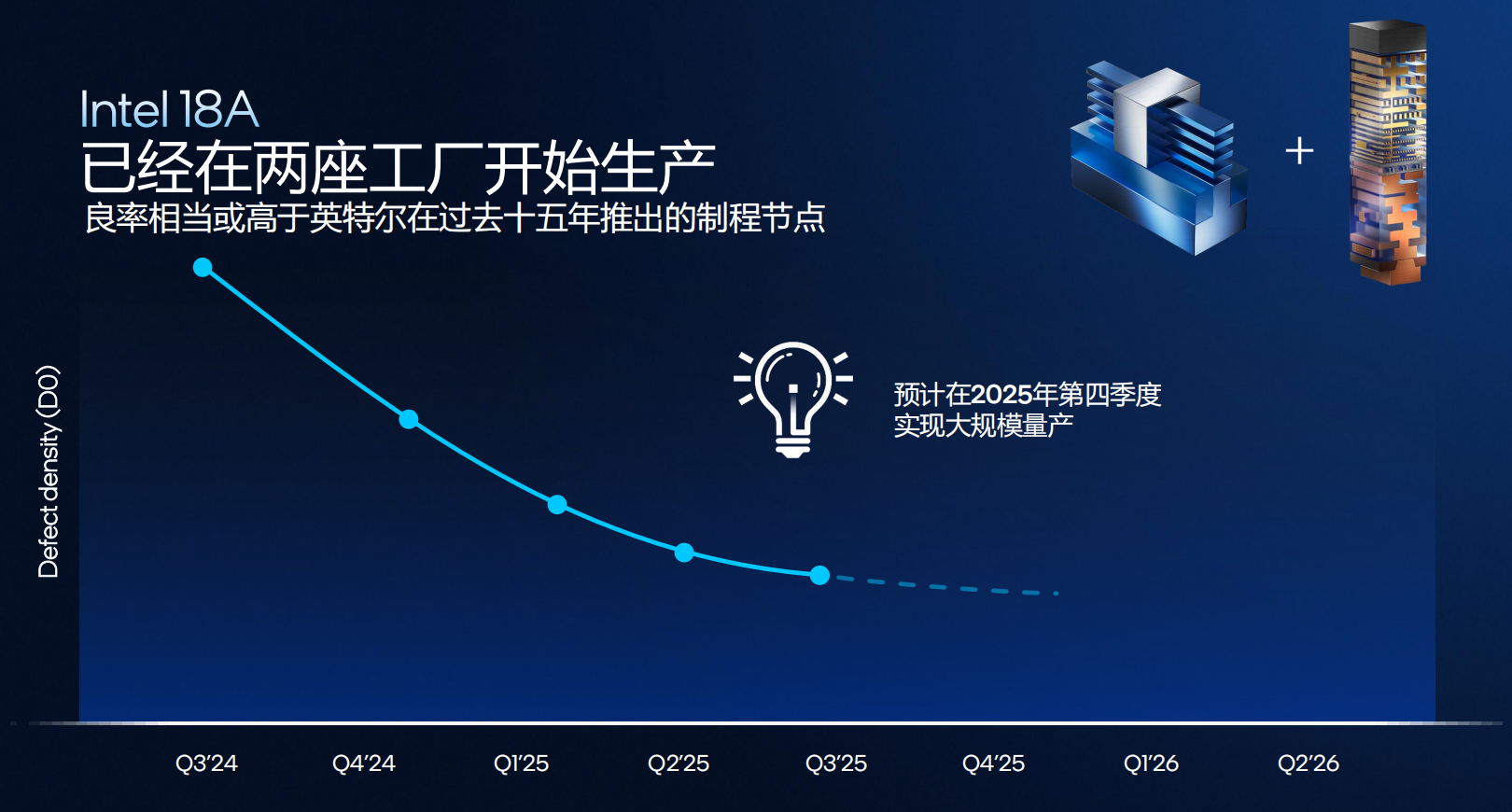
PowerVia背部供电:将供电网络下沉至晶圆背面,信号与供电分层,提升10%单元利用率并降低约30%压降,为高频电路提供更干净的电流。
RibbonFET技术:电流通道被四面环绕,增强晶体管控制能力与响应速度,降低漏电与功耗,在同功耗下性能提升15%以上。
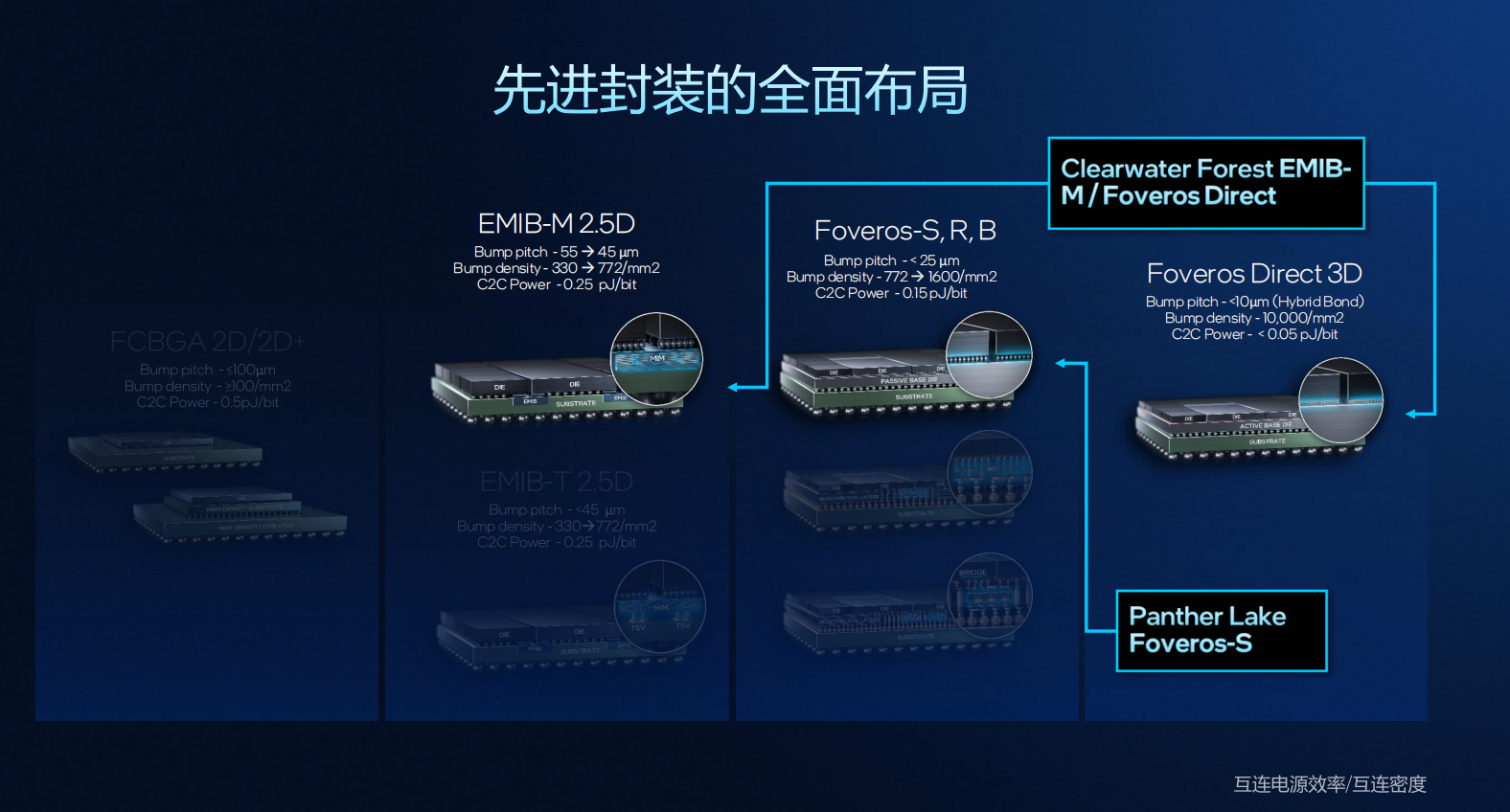
先进封装:英特尔在先进封装领域形成了从2D到3D的全栈布局:FCBGA实现稳定可靠的封装连接;EMIB 2.5D实现更高密度与更低功耗的芯片互连;2019年量产的Foveros-S技术支持更高集成密度与能效;Foveros Direct 3D技术,采用铜对铜混合键合,实现超高密度、低延迟、低功耗互连,已在Clearwater Forest中率先量产应用。
尤为值得一提的是,RibbonFET与PowerVia技术相互协同,构成Intel 18A在密度与能效同步提升的关键基础。与上一代相比,Intel 18A实现:相同性能下功耗降低25%;相同功耗下每瓦性能提升15%以上;芯片密度提升30%,显著增强集成潜力与能效表现。
英特尔在最新一代产品中展示了完整的系统级封装创新路线。其中,Panther Lake 和 Clearwater Forest 分别面向消费端与服务器端,代表了英特尔在Foveros、EMIB及3D封装技术上的最新成果。
Panther Lake 采用 Foveros-S 工艺,将计算、图形及平台控制模块与被动基础模块垂直互连,实现高密度、高能效的堆叠设计,特别适用于笔电与AI PC等能耗敏感场景。
Clearwater Forest 则融合 EMIB-M 与 Foveros Direct 3D 两项关键技术。CPU与I/O模块首先通过Foveros Direct与有源基底层堆叠,再通过EMIB-M桥接至基板,形成“三明治式”结构,大幅提升互连带宽与散热效率,为超大规模服务器提供高性能解决方案。
CPU:三层混合架构的再进化
自Meteor Lake 起,英特尔开启了混合核心架构的演进之路。性能核(P 核)、能效核(E 核)与低功耗能效核(LPE 核)形成了 CPU 的三层分工体系。

例如,Meteor Lake采用的Crestmont架构,为低功耗岛带来了初步的能效优势;而在Arrow Lake阶段,E核升级为 Skymont,大幅提升了多线程性能;紧接着Lunar Lake则把Skymont带入低功耗岛,实现了能效与性能的平衡。
到了 Panther Lake,英特尔没有推倒重来,而是在原有基础上再度强化:性能核从 Lion Cove 升级为 Cougar Cove;能效核从 Skymont 迭代为 Darkmont;低功耗能效核同样获得架构优化。英特尔技术专家指出:“P核主攻高性能响应,E 核擅长多线程处理,而 LPE 核则优化系统的日常功耗。三者协同,是 Panther Lake 整体能效领先的关键。”
Cougar Cove 是 Panther Lake 的性能核心,基于 Intel 18A 工艺打造。它保留了 18 个执行端口,并将 L3 缓存容量从 12MB 提升至 18MB,提升幅度达 50%。更大的缓存让复杂任务执行更流畅,也为多任务切换提供了更充裕的带宽空间。
在功耗控制上,英特尔首次将 AI 启发式电源管理算法应用于 CPU 内部。该系统可实时学习用户的使用习惯,根据负载变化动态调整功率分配,从而在性能释放与能耗控制之间找到最优解。
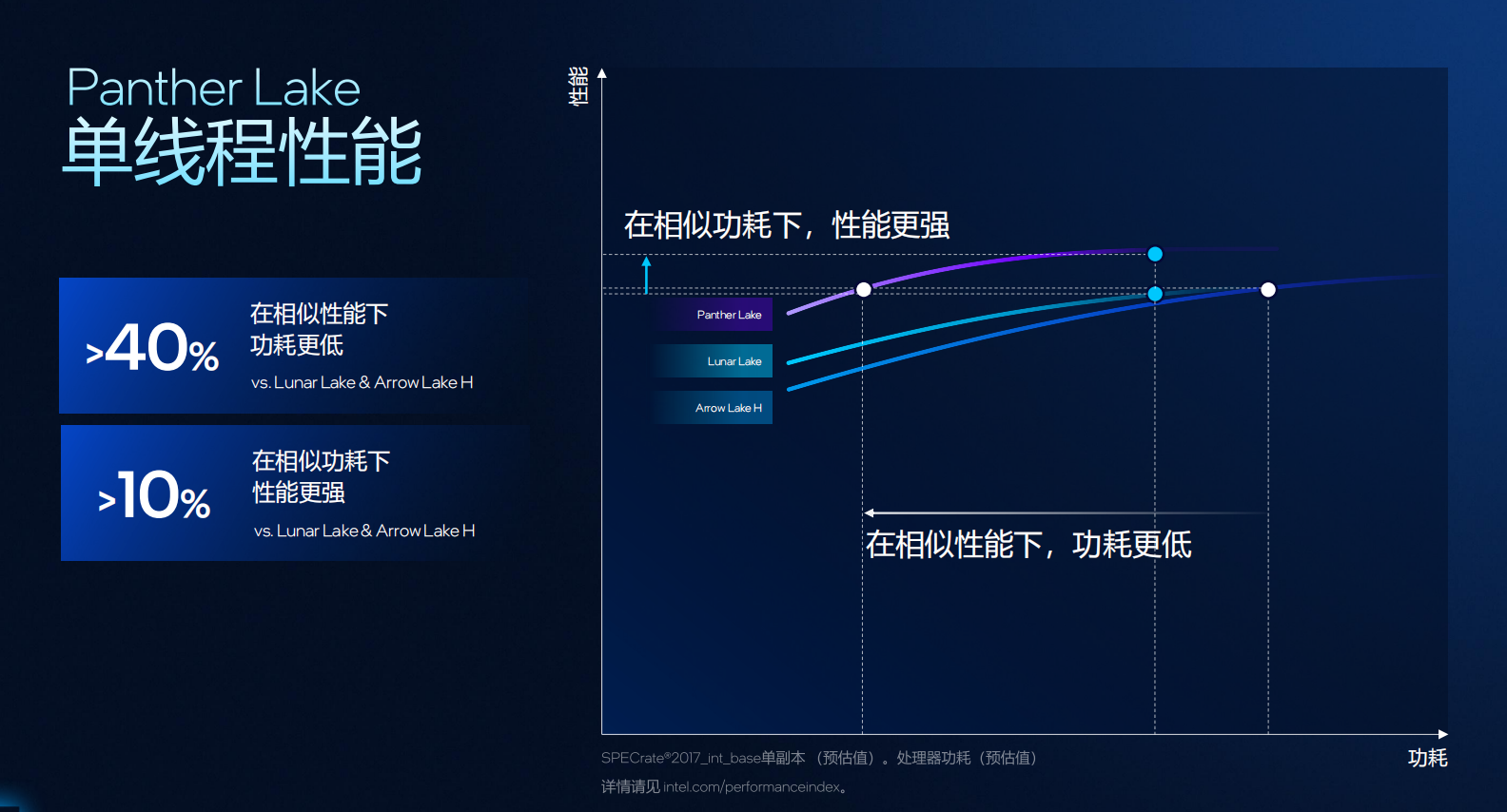
此外,Cougar Cove 还带来了三项核心优化:1)内存消歧(Memory Disambiguation),通过智能预测与恢复机制,打破传统内存访问顺序限制,让并行指令执行更高效。2)TLB 增强,地址转换缓存容量提升 1.5 倍,显著减少页表访问延迟,加快复杂任务响应。3)分支预测优化,基于全新算法迭代,预测准确度更高、延迟更低,使有效计算时间进一步增加。凭借这些改进,Panther Lake 在相同性能下的功耗可降低超过 40%,而在相同功耗下,单线程性能提升 约 10%。
Darkmont是基于Skymont架构的深度演进版本,同样得益于 18A 工艺,使其在面积、带宽与能耗之间取得更高平衡。它保留了 26 个调度端口,并将 L2 缓存扩容至 4MB,带宽保持在 128bit。同时,英特尔将性能核中的 内存消歧技术 也引入了能效核,进一步提升内存访问效率,优化多线程并行性能。
Darkmont的另一项亮点是Nanocode技术。相比传统 Microcode,Nanocode 能将复杂指令拆分为更细粒度的硬件操作单元,实现更灵活的硬件调度与资源利用。在Panther Lake 上,Nanocode的覆盖场景更广,可在更多负载类型中释放潜能。
除此之外,英特尔还在能效核中强化了:分支预测精度 —— 提高并行负载处理效率;动态预取控制 —— 按负载特征实时调整数据预取策略,既提升性能又控制功耗。
综合结果显示,Panther Lake 在相似性能下功耗降低 40%,在相似功耗下性能提升 10%;多线程性能相较 Lunar Lake 提升超过 50%,而功耗则降低约 30%。
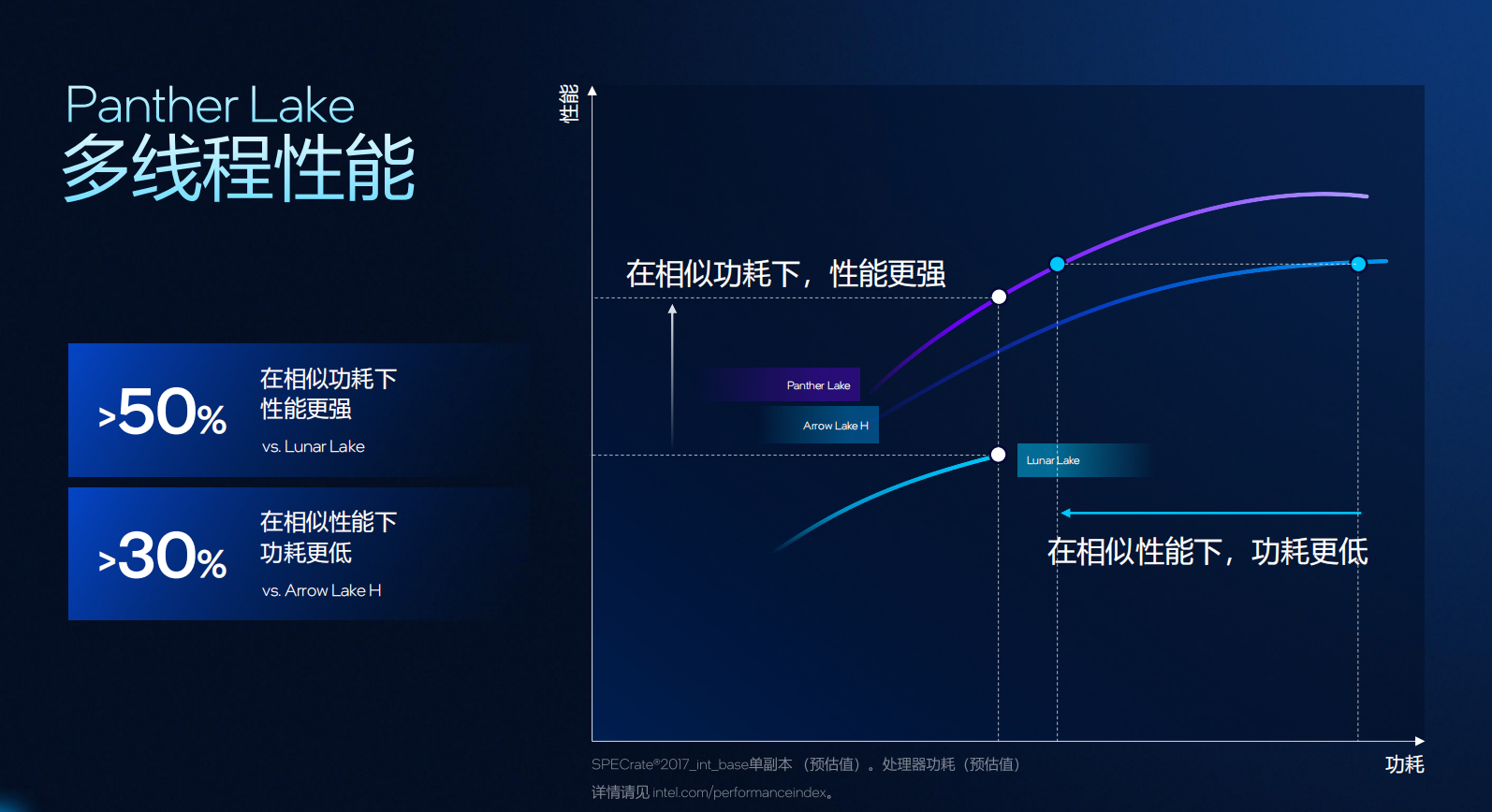
在SoC层面,Panther Lake 提供两种主要配置:1)8 核版本,4个性能核 + 4 个低功耗能效核,定位高能效轻薄平台;2)16 核版本,4 个性能核 + 8 个能效核 + 4 个低功耗能效核,面向高性能与创作场景。
所有核心共享一个 L3 缓存环,性能核各自拥有独立 L2,每四个能效核共享一个 4MB L2,低功耗能效核同样拥有 4MB L2。相比前代,低功耗区域的缓存容量翻倍,使其能承担更复杂的负载。
同时,Panther Lake 延续了 Lunar Lake 的设计优势,在低功耗岛中引入 内存端缓存(Memory-side Cache),大幅减少系统主内存访问次数,提升整体响应速度与能效表现。
硬件的优化只有与操作系统的智能调度结合,才能真正释放潜能。英特尔在 Panther Lake 中引入了改进版 硬件线程调度器(Hardware Thread Director)。它由两部分组成:分类模型与反馈表。分类模型可识别不同类型的任务负载,判断其更适合运行在性能核、能效核还是低功耗核上;反馈表则实时向操作系统提供每类核心的性能与能效指数,让操作系统能基于真实状态,做出更精确的线程分配决策。
这代的改进包括:重新校准分类模型,使其匹配 Panther Lake 新架构特性;扩展反馈信息来源,不仅考虑温度与频率,还整合 OEM 电源模式与系统级信息;调度逻辑从“单向调用”升级为“三层并行”,支持跨 P/E/LPE 核的高频切换。这种智能调度的实际效果十分显著。
在 Teams 视频会议等轻负载场景下,系统会优先启用低功耗能效核,显著降低功耗;在生产力应用(UL Procyon)中,系统能在突发负载时迅速切换至性能核,确保响应速度;而在游戏场景中(如《控制》DX12),当操作系统处于“混合模式”时,调度策略会自动压缩 CPU 功耗,为集成 GPU 腾出功率空间,从而带来约 10% 的帧率提升。
Panther Lake 的架构优化最终通过系统软件体现给用户。英特尔构建了一个完整的软硬件协同堆栈,从 OEM 的性能模式(如“野兽模式”“平衡模式”),到 SoC 的电源管理与硬件调度,都通过 DTT(Dynamic Tuning Technology) 与 微软 PPM 平台接口进行统一管理。
尤其在笔记本的电池模式下,Panther Lake 新增了智能自适应平衡机制。系统会在后台实时监控负载情况,在性能模式与节能模式间自动切换,无需用户手动干预,即可获得最佳性能与续航平衡。测试数据显示,在 UL Procyon 和 CineBench 2024 单线程场景下,该机制可带来 最高 19% 的性能提升,同时保持功耗稳定。
GPU迈入 Xe3时代
英特尔在 Panther Lake 上的 GPU 选择,从一开始就瞄准了“可扩展”和“高吞吐”。客户端集显的路线图从 Xe、到 Xe2、再到今天的 Xe3,是一条持续演进的主线。

Panther Lake把客户端集显正式带入Xe3 时代,并明确下一站是功耗更优的Xe3P。这代的关键词是“扩展性”。集显的基本构建单元是“渲染切片”,而每个切片的核心算力来自 Xe Core。从 Xe2 到 Xe3,每个切片中的 Xe Core 数量由 4 个提升到 6 个。这一步直接把同面积下的并行能力与 AI 算力上限一起抬高。
产品上,Panther Lake 给出两档规格。入门是 4Xe,旗舰是 12Xe,这是迄今规模最大的英特尔集显。4Xe 已能覆盖日常与轻量 AI;12Xe 面向重负载图形与端侧 AI 应用。
对比 Lunar Lake 的 Xe2,Xe3 性能提升可超过 50%。如果回看早期 Xe 架构(如 Arrow Lake H),每瓦性能提升可超过 40%。
回到最初的问题:这代 GPU 解决了什么?它首先解决了“规模”——切片更大、Core 更多、缓存更宽,带来了可线性放大的空间。它同时解决了“效率”——从 FP8 到 INT2 的精度阶梯、从动态 RT 调度到 URB 颗粒度同步,让每一瓦电都更值钱。最后它也解决了“落地”——4Xe 到 12Xe 的 SKU 梯度,把体验与成本拉成了可选项,而不是单一答案。

NPU:让AI真正跑在本地
英特尔在 Panther Lake 上的 NPU 设计,目标很直接:架构一致、效率更高、覆盖更多 AI PC。要做到这一点,第一性问题是同样芯片面积,如何算得更多、更省电。
答案是全新一代 NPU5:在不增大 Slice 尺寸的前提下,把每个神经计算引擎的 MAC 单元做大。更大的 MAC 意味着更高的矩阵运算密度,而矩阵运算正是 AI 推理的核心。因此,NPU5 在每个 Slice 内将“6 个小单元”整合为“3 个大单元”,单元数更少但单元能力翻倍。这种调整让Die 面积利用率更高、数据路径更短、控制更简单。
效率之外,算力形态也针对新负载做了更新。英特尔在 NPU5 中加入原生 8-bit 计算支持,让主流推理任务算力直接“翻倍”、精度仍在可控范围。同时补齐原生 FP8 数据类型与激活函数路径优化,在“准确率—吞吐—功耗”三角中找到更优解。综合下来,NPU5 峰值可达约 50 TOPS,为端侧 LLM、视觉与语音任务提供稳定底座。
把视角拉到整个平台,Panther Lake SoC 总算力可至约 180 TOPS。粗分工是:CPU 约 10 TOPS 处理轻量与控制类 AI,NPU 约 50 TOPS 负责持续低功耗推理,GPU 约 120 TOPS 承担高吞吐任务。
算力准备好后,关键是怎么用起来。英特尔提出了“PC 驱动的 AI 智能体”路线,把生成式模型带到端侧执行。回顾八年演进:2015 年侧重感知(CNN),2018 年流行增强(美颜、去噪、超分),如今进入生成(图像、音频、代码、文本)。下一阶段是智能体:它要能推理与反思,会调工具接环境,还能带记忆做多步任务。这要求端侧模型具备更长的上下文、更强的工具链、更稳的能效曲线。
好消息是,端侧模型能力在过去一年显著跃迁。上下文从4K 提升到可达 128K,从“小册子”跨到“长文档”。即便在 <14B 的约束下,小模型在若干基准上逼近专家水平。这正是把智能体落到本地的时间窗口,也正需要 NPU5 与 Xe3 的双引擎托底。
为让开发者“即插即用”,英特尔提供两条推理流水线(Pipeline)。第一条是OpenVINO + NNCF,主打高性能推理与高质量量化。第二条是WindowsML 路径,框架无关、易接入,底层重定向到 OpenVINO 发挥硬件潜力。工具与驱动打通后,从模型到端侧部署的摩擦被尽量降低。
在体验侧,智能渲染是 Xe3 + NPU 的另一张王牌。传统渲染很长:光栅打底 + 光追补细节 + 一串后处理,画质好但管线“重”。引入 XeSS(AI 超分辨率) 后,先低分渲染、再 AI 放大,整体耗时立刻缩短。官方给出的测算是:仅 XeSS 超分一步,就能把整条 Pipeline 长度缩短约 40%。升级到 XeSS 2 后,再加一段帧生成(Frame Generation),在两帧高分影像之间插入同分辨率高质量中间帧。帧更“满”的同时,总耗时比单纯超分更短、交互延迟更低。在 Xe3 上,英特尔还加入 MFG 多帧生成,一次“补多帧”,FPS 更高、功耗更稳,这就是“AI+图形”协同的直观收益。
把所有拼图拼起来,可以得到一个清晰结论。NPU5 负责把端侧推理的“每瓦效率”推上去,Xe3 负责把吞吐与画质的“每帧体验”拉起来,CPU 维持全局控制与轻载弹性。在这套分工下,Panther Lake 不仅有“180 TOPS 的总量”,更有“任务—算力—能耗”的匹配度。这正是 AI PC 从“能跑”走向“能大规模、能持久跑”的关键分水岭。

无线与影像:连得更快,看得更清
在 Panther Lake 平台上,英特尔把无线通信与影像处理都升级到了系统级。目标很明确——让 AI PC 不仅“跑得快”,还能“连得稳、拍得清”。
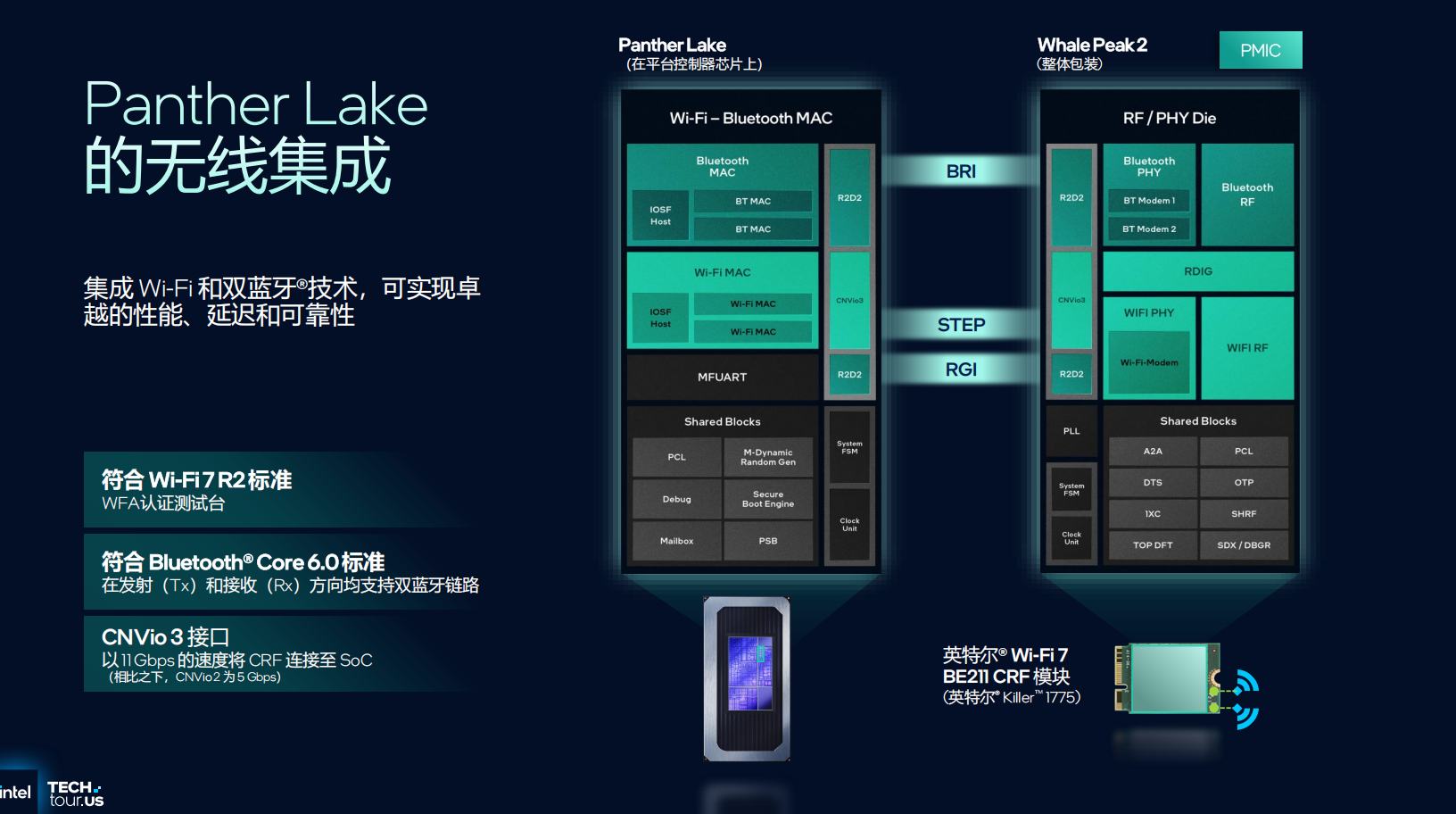
l 无线连接
Panther Lake 集成了最新的 Wi-Fi 7 与 蓝牙 6.0 技术,通过软硬件一体化设计,实现高速、低延迟和更高能效。Wi-Fi 7 提供 320 MHz 信道、4K QAM 调制、WPA3 安全加密,并新增四大功能:多链路重配置:动态切换频段,节能又提速;限定 TWT:让慢设备也能稳定收发;单链路 eMLSR:可在单天线下保持并发性能,降低功耗;P2P 信道协同:终端间直连传输,减少延迟。
蓝牙 6.0 则支持 LE Audio,功耗降低 50%,音质更好,支持多流音频、Auracast™ 广播及助听器连接。同时加入 飞行时间(ToF)与相位测距,定位精度可达 10 cm。双蓝牙内核设计让通信距离延长至 52 米,灵敏度提升 5 dB。
全新的 ICPS 5.0 无线套件引入 AI 感知 QoS 与流量优先级管理,语音/视频延迟降低 70%,网页与应用加载时间缩短 35%。
l 影像处理
Panther Lake 采用集成式 IPU 7.5,可直接共享系统内存,并与CPU/GPU/NPU 协同工作,实现实时 AI 图像优化。相较离散方案,它更快、更省电,也支持多摄并发与 1080p @ 120 Hz 慢动作视频。
IPU 7.5 的三大升级:1)双重曝光 HDR:长短曝光合成,亮部细节与暗部层次兼顾,功耗降低 1.5 W;2)AI 降噪:借助 NPU 和 GPU 实时去噪,弱光画面更纯净、帧率更高;3)AI 局部色调映射:智能调整对比度,无光晕伪影,保持色彩一致性。
英特尔还提供完整的 IPU 软件栈与 SDK,支持 Windows、ChromeOS 与 Linux,帮助 OEM 快速完成相机调校。
结语
如果说 Lunar Lake 让 AI PC “能用”,那 Panther Lake 就是让它“能大规模普及”。18A 制程解决了性能与能效的根问题;Foveros 封装让芯片拼得更灵活;三层混合架构让算力调度更聪明;再加上 GPU 和 NPU 的 AI 加速,这代产品有望成为 AI PC 真正普及的起点。
Panther Lake 是英特尔 AI PC 战略的关键转折点——也是 AI 从云端走向每一台个人设备的分水岭。
责任编辑:duqin
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号