推理芯片市场,HBM迎来了挑战者
2025-08-06
10:19:02
来源: 互联网
点击
在过去几年蓬勃发展的人工智能市场,除了英伟达以外,还有一个芯片赢家,那就是SK海力士。据财务数据显示,2025年第二季度,SK海力士获得了162.3 亿美元的营收,利润高达51亿美元,同比增长69.8%。这让他们超过了过去几十年一直排在其前面的三星,成为全球第一的DRAM供应商。
其中,营收占比77%的HBM,是SK海力士能走到当前的最重要的筹码。
作为一种特殊的 DRAM,HBM借助垂直堆叠,并通过硅片内部名为 TSV(硅通孔)的细线连接到处理器。由于TSV 允许直接连接多个 HBM DRAM 芯片,这就使其能够提高整体内存带宽。正是因为这种优势,让HBM能够在大模型的训练时代发生了重要的作用。但随之而来的成本压力,也是显而易见的。
于是,到了推理时代,GDDR找到了可乘之机。
人工智能,变了
其实在大模型出现之前,人工智能已经经历了漫长的进化,也呈现出了不同的特征。例如,传统AI主要专注于基于输入模型进行数据分析和预测,且局限于有限的输入/输出模态(例如文本到网页结果)。
在Rambus半导体IP产品管理总监Nidish Kamath看来,这个阶段的人工智能可以称之为AI 1.0时代。这个阶段典型的AI应用有语音助手、推荐引擎和搜索平台,这些系统在处理相对简单的任务(如语音转语音、文本转文本、语音转文本)方面表现出色,但无法处理复杂多样的内容创作,例如跨多种模型的音乐。
之后,随着大模型的到来,人工智能正式迈入了AI 2.0时代。
因为LLM能够理解复杂输入(包括文本、图像或语音),并生成从传统文本响应到更高级形式(如代码、图像、视频甚至3D模型)的输出。正是因为这些特征让AI 2.0时代开启了跨多种模态的无限创意与创新可能性。这些特性在GPT-4、PaLM2、ERNIE 4.0、Inflection-2、Gemini 1.5和Olympus等LLM中均有体现,并且正在扩展至更多边缘和终端应用场景。
Nidish Kamath指出,AI 2.0应用的迅猛发展对AI训练和推理工作流的内存带宽和容量提出了巨大的要求。例如在AI训练方面,对应的AI模型规模正迅速扩大:Chat GPT-3的1750亿参数与Chat GPT-4的1.76万亿参数相比相形见绌,突显出对内存带宽和容量需求的持续增长。
与此同时,许多AI应用正从数据中心向边缘和终端迁移,这对现有的内存系统提出了更高要求。于是,采用GDDR内存的GPU成为了推理引擎的首选。
这也让GDDR在更多的AI推理芯片中找到了机会。
GDDR,顺势而为
顾名思义,GDDR (Graphics Double Data Rate)是最初是一种专为GPU设计的存储,是为渲染绘图所必需的高速数据传输而设计。在实际应用中,GDDR可在时钟周期的正缘和负缘运作,有效地将数据传输率提高一倍。于是,每个GPU 都有专用GDDR 存储,并由存储控制器管理,可最佳化数据流并减少延迟。随着时间过去,新版本的频宽和效率得到提高,进而增强了整体绘图效能。
“与HBM相比,其性价比特性使其适合在边缘网络和物联网终端设备等领域进行大规模部署。”Nidish Kamath说。他进一步指出,HBM采用2.5D/3D架构,以更宽的接口和更低的时钟频率(相较于GDDR7)为AI/ML和HPC应用提供更高的总吞吐量和更高的每瓦带宽效率。然而,其实现成本更高、更复杂,对于强度较低的任务而言可能并非必要。此外,AI推理应用通常使用比训练时精度更低的优化模型参数。这意味着与训练基础设施相比,其对内存和总带宽的要求更低。
这时候,GDDR7就完美契合了这些要求。根据JEDEC 在去年 3 月宣布的标准, GDDR7 单芯片数据速率高达 192GB/s,芯片密度高达 32Gb,并具备最新的数据完整性特性。据介绍,这个高数据速率是通过使用 3 个电平(+1、0、-1)的 PAM3(脉冲幅度调制)在 2 个周期内传输 3 位来实现的,而当前的 GDDR6 一代则使用 NRZ(不归零)在 2 个周期内传输 2 位。
“一方面,它能在较低的内存容量点上提供高带宽;另一方面,与HBM相比,其更简单的封装也降低了GDDR7系统的整体内存成本——这对于部署规模可能比AI训练更大的推理系统而言是一个重要因素。”Nidish Kamath告诉半导体行业观察。
Nidish Kamath同时承认,对于AI推理应用,设计人员有多种内存选择。鉴于DDR4内存在笔记本电脑和台式机系统中的长期成功应用历史,初期系统采用了这种经过市场长期检验的技术。如今,DDR5内存也已成为一个可选项。另一个选择则是LPDDR,该技术已在数十亿部手机中得到部署,其最新一代为LPDDR5X。
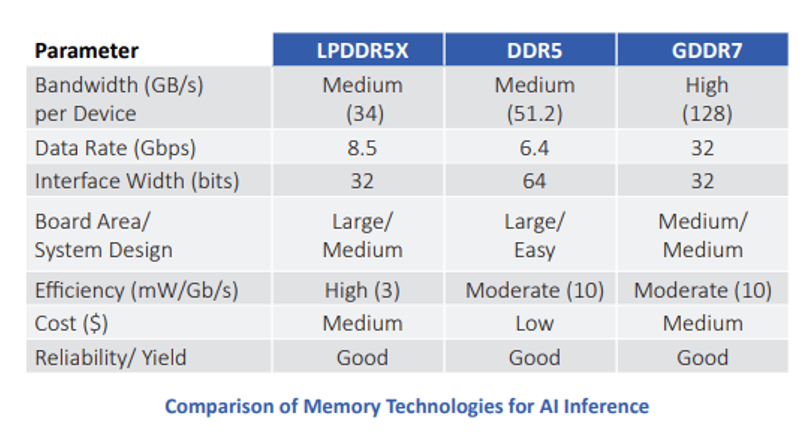
“在带宽这一关键参数上,GDDR7内存的表现尤为出色。一个GDDR7器件在32 Gbps的数据速率和32位宽接口的配置下,可提供128 GB/s的内存带宽,是其他任何替代方案的两倍还多。GDDR7内存为AI推理应用提供了最佳的速度、带宽和延迟综合性能。”Nidish Kamath强调。
面对这种新趋势,Rambus正在全力以赴。
Rambus的IP赋能
作为一家业界领先的Silicon IP和芯片提供商,凭借着35年的技术领先地位,Rambus以创新为基础,打造了包括基础技术、半导体IP和芯片在内的三大半导体解决方案。在基础技术方面,Rambus在35年里开发了约2800项的专利;在半导体IP方面,Rambus则提供了包括接口IP和安全IP在内的两类领先产品;在芯片产品方面,Rambus为DDR4和DDR5内存模块提供除了DRAM颗粒以外所有内存模块所需的芯片组。
也正是在这些积累的基础上,Rambus带来了 GDDR7控制器。
据Nidish Kamath介绍,为了提升内存带宽,GDDR7采用PAM3信令以取代NRZ(PAM2)信令。这一新方案使内存能够在两个周期内传输“3比特信息”,与同等时钟频率的GDDR6相比,数据传输量增加了50%,从而将实际速率上限提升至40 Gbps。而为了确保在如此高的速度下实现可靠的数据传输,GDDR7整合了先进的FEC(前向纠错)机制。这有助于缓解因高频操作及PAM3信令所固有的信号完整性挑战。
“通过PAM3信令,提供了一种功能齐全、节省带宽的内存实现解决方案,将GDDR7内存的数据速率提升至40 Gbps,吞吐量提升至160 GB/s,推动了先进GDDR内存在前沿AI加速器、图形处理和高性能计算应用中的使用。”Nidish Kamath指出。“作为在信号完整性(SI)和电源完整性(PI)领域公公认的领导者,Rambus拥有超过30年的经验,致力于助力实现市场上最高性能的系统。借助像Rambus这样公司的专业知识和协助,设计者可以更好地应对因数据传输速率增加而带来的信号完整性挑战。”Nidish Kamath强调。
基于此,Rambus推出了极具优势的业界首款 GDDR7 内存控制器 IP,具体如下所示:
1、Rambus GDDR7内存控制器IP提供业界领先的GDDR7性能,每引脚速率高达40 Gbps,每个GDDR7内存设备可提供160 GB/s的可用带宽。
2、Rambus的GDDR7控制器核专为需要高内存吞吐量、高时钟频率和完全可编程性的应用而设计。
3、该控制器核通过AXI接口或简单的本地接口接受命令,并将其转换为GDDR7 SGRAM设备所需的命令序列。它也支持所有低功耗模式。
4、该核心使用先进调度算法来重新排序队列中的用户请求,以此最大限度地提高总线效率,并减少DRAM访问规则造成的内存总线空闲时间。核心在维持访问限制和一致性规则的同时,会选择处理队列中的下一个最佳请求,以此实现高效率,并将所有请求的延迟时间降至最低。核心使用内存库管理技术监测每个GDDR7 SGRAM的状态。只有在必要时才会打开或关闭内存库,从而最大限度地减少访问延迟。
5、这种核支持所有GDDR7的链路功能,包括PAM3,NRZ信号传输,带读写重试的CRC,数据扰乱,数据投毒,clamshell模式和DQ逻辑重映射。
总而言之,GDDR7内存控制器IP功能包括:
1、支持以每引脚高达 40 Gb/s 的速率运行
2、支持包括PAM3和NRZ信号在内的所有GDDR7链路功能
3、支持多种GDDR7设备尺寸和速率
4、专门针对各种流量情况进行优化,可实现高效率和低延迟
5、灵活的AXI接口支持
6、专门针对各种流量情况进行优化,可实现高效率和低延迟
7、可靠性、可用性和可维护性(RAS)功能,例如端到端数据路径奇偶校验、存储寄存器奇偶校验保护等
8、全方位的内存测试支持
9、提供针对客户和第三方物理层的集合支持
除了GDDR7 控制器IP以外,Rambus其实还有HBM控制器IP等一系列产品。凭借这些领先IP,Rambus已然成为人工智能芯片市场不可或缺的参与者。
其中,营收占比77%的HBM,是SK海力士能走到当前的最重要的筹码。
作为一种特殊的 DRAM,HBM借助垂直堆叠,并通过硅片内部名为 TSV(硅通孔)的细线连接到处理器。由于TSV 允许直接连接多个 HBM DRAM 芯片,这就使其能够提高整体内存带宽。正是因为这种优势,让HBM能够在大模型的训练时代发生了重要的作用。但随之而来的成本压力,也是显而易见的。
于是,到了推理时代,GDDR找到了可乘之机。
人工智能,变了
其实在大模型出现之前,人工智能已经经历了漫长的进化,也呈现出了不同的特征。例如,传统AI主要专注于基于输入模型进行数据分析和预测,且局限于有限的输入/输出模态(例如文本到网页结果)。
在Rambus半导体IP产品管理总监Nidish Kamath看来,这个阶段的人工智能可以称之为AI 1.0时代。这个阶段典型的AI应用有语音助手、推荐引擎和搜索平台,这些系统在处理相对简单的任务(如语音转语音、文本转文本、语音转文本)方面表现出色,但无法处理复杂多样的内容创作,例如跨多种模型的音乐。
之后,随着大模型的到来,人工智能正式迈入了AI 2.0时代。
因为LLM能够理解复杂输入(包括文本、图像或语音),并生成从传统文本响应到更高级形式(如代码、图像、视频甚至3D模型)的输出。正是因为这些特征让AI 2.0时代开启了跨多种模态的无限创意与创新可能性。这些特性在GPT-4、PaLM2、ERNIE 4.0、Inflection-2、Gemini 1.5和Olympus等LLM中均有体现,并且正在扩展至更多边缘和终端应用场景。
Nidish Kamath指出,AI 2.0应用的迅猛发展对AI训练和推理工作流的内存带宽和容量提出了巨大的要求。例如在AI训练方面,对应的AI模型规模正迅速扩大:Chat GPT-3的1750亿参数与Chat GPT-4的1.76万亿参数相比相形见绌,突显出对内存带宽和容量需求的持续增长。
与此同时,许多AI应用正从数据中心向边缘和终端迁移,这对现有的内存系统提出了更高要求。于是,采用GDDR内存的GPU成为了推理引擎的首选。
这也让GDDR在更多的AI推理芯片中找到了机会。
GDDR,顺势而为
顾名思义,GDDR (Graphics Double Data Rate)是最初是一种专为GPU设计的存储,是为渲染绘图所必需的高速数据传输而设计。在实际应用中,GDDR可在时钟周期的正缘和负缘运作,有效地将数据传输率提高一倍。于是,每个GPU 都有专用GDDR 存储,并由存储控制器管理,可最佳化数据流并减少延迟。随着时间过去,新版本的频宽和效率得到提高,进而增强了整体绘图效能。
“与HBM相比,其性价比特性使其适合在边缘网络和物联网终端设备等领域进行大规模部署。”Nidish Kamath说。他进一步指出,HBM采用2.5D/3D架构,以更宽的接口和更低的时钟频率(相较于GDDR7)为AI/ML和HPC应用提供更高的总吞吐量和更高的每瓦带宽效率。然而,其实现成本更高、更复杂,对于强度较低的任务而言可能并非必要。此外,AI推理应用通常使用比训练时精度更低的优化模型参数。这意味着与训练基础设施相比,其对内存和总带宽的要求更低。
这时候,GDDR7就完美契合了这些要求。根据JEDEC 在去年 3 月宣布的标准, GDDR7 单芯片数据速率高达 192GB/s,芯片密度高达 32Gb,并具备最新的数据完整性特性。据介绍,这个高数据速率是通过使用 3 个电平(+1、0、-1)的 PAM3(脉冲幅度调制)在 2 个周期内传输 3 位来实现的,而当前的 GDDR6 一代则使用 NRZ(不归零)在 2 个周期内传输 2 位。
“一方面,它能在较低的内存容量点上提供高带宽;另一方面,与HBM相比,其更简单的封装也降低了GDDR7系统的整体内存成本——这对于部署规模可能比AI训练更大的推理系统而言是一个重要因素。”Nidish Kamath告诉半导体行业观察。
Nidish Kamath同时承认,对于AI推理应用,设计人员有多种内存选择。鉴于DDR4内存在笔记本电脑和台式机系统中的长期成功应用历史,初期系统采用了这种经过市场长期检验的技术。如今,DDR5内存也已成为一个可选项。另一个选择则是LPDDR,该技术已在数十亿部手机中得到部署,其最新一代为LPDDR5X。
“在带宽这一关键参数上,GDDR7内存的表现尤为出色。一个GDDR7器件在32 Gbps的数据速率和32位宽接口的配置下,可提供128 GB/s的内存带宽,是其他任何替代方案的两倍还多。GDDR7内存为AI推理应用提供了最佳的速度、带宽和延迟综合性能。”Nidish Kamath强调。
面对这种新趋势,Rambus正在全力以赴。
Rambus的IP赋能
作为一家业界领先的Silicon IP和芯片提供商,凭借着35年的技术领先地位,Rambus以创新为基础,打造了包括基础技术、半导体IP和芯片在内的三大半导体解决方案。在基础技术方面,Rambus在35年里开发了约2800项的专利;在半导体IP方面,Rambus则提供了包括接口IP和安全IP在内的两类领先产品;在芯片产品方面,Rambus为DDR4和DDR5内存模块提供除了DRAM颗粒以外所有内存模块所需的芯片组。
也正是在这些积累的基础上,Rambus带来了 GDDR7控制器。
据Nidish Kamath介绍,为了提升内存带宽,GDDR7采用PAM3信令以取代NRZ(PAM2)信令。这一新方案使内存能够在两个周期内传输“3比特信息”,与同等时钟频率的GDDR6相比,数据传输量增加了50%,从而将实际速率上限提升至40 Gbps。而为了确保在如此高的速度下实现可靠的数据传输,GDDR7整合了先进的FEC(前向纠错)机制。这有助于缓解因高频操作及PAM3信令所固有的信号完整性挑战。
“通过PAM3信令,提供了一种功能齐全、节省带宽的内存实现解决方案,将GDDR7内存的数据速率提升至40 Gbps,吞吐量提升至160 GB/s,推动了先进GDDR内存在前沿AI加速器、图形处理和高性能计算应用中的使用。”Nidish Kamath指出。“作为在信号完整性(SI)和电源完整性(PI)领域公公认的领导者,Rambus拥有超过30年的经验,致力于助力实现市场上最高性能的系统。借助像Rambus这样公司的专业知识和协助,设计者可以更好地应对因数据传输速率增加而带来的信号完整性挑战。”Nidish Kamath强调。
基于此,Rambus推出了极具优势的业界首款 GDDR7 内存控制器 IP,具体如下所示:
1、Rambus GDDR7内存控制器IP提供业界领先的GDDR7性能,每引脚速率高达40 Gbps,每个GDDR7内存设备可提供160 GB/s的可用带宽。
2、Rambus的GDDR7控制器核专为需要高内存吞吐量、高时钟频率和完全可编程性的应用而设计。
3、该控制器核通过AXI接口或简单的本地接口接受命令,并将其转换为GDDR7 SGRAM设备所需的命令序列。它也支持所有低功耗模式。
4、该核心使用先进调度算法来重新排序队列中的用户请求,以此最大限度地提高总线效率,并减少DRAM访问规则造成的内存总线空闲时间。核心在维持访问限制和一致性规则的同时,会选择处理队列中的下一个最佳请求,以此实现高效率,并将所有请求的延迟时间降至最低。核心使用内存库管理技术监测每个GDDR7 SGRAM的状态。只有在必要时才会打开或关闭内存库,从而最大限度地减少访问延迟。
5、这种核支持所有GDDR7的链路功能,包括PAM3,NRZ信号传输,带读写重试的CRC,数据扰乱,数据投毒,clamshell模式和DQ逻辑重映射。
总而言之,GDDR7内存控制器IP功能包括:
1、支持以每引脚高达 40 Gb/s 的速率运行
2、支持包括PAM3和NRZ信号在内的所有GDDR7链路功能
3、支持多种GDDR7设备尺寸和速率
4、专门针对各种流量情况进行优化,可实现高效率和低延迟
5、灵活的AXI接口支持
6、专门针对各种流量情况进行优化,可实现高效率和低延迟
7、可靠性、可用性和可维护性(RAS)功能,例如端到端数据路径奇偶校验、存储寄存器奇偶校验保护等
8、全方位的内存测试支持
9、提供针对客户和第三方物理层的集合支持
除了GDDR7 控制器IP以外,Rambus其实还有HBM控制器IP等一系列产品。凭借这些领先IP,Rambus已然成为人工智能芯片市场不可或缺的参与者。
责任编辑:Ace
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号