存算一体瓶颈,中国团队实现突破
2025-07-03
11:29:55
来源: 李寿鹏
点击
人工智能的高速发展,给芯片的算力带来了新挑战,伴之而来的就是越来越严峻的“内存墙”问题。这一切,则需要从统治大半个处理器芯片江湖的冯诺依曼架构说起。作为一个被广泛应用的架构,冯·诺依曼架构推广了存储程序概念,使计算机更加灵活,更易于重新编程。这种设计将数据和指令存储在同一内存中,简化了硬件设计,并实现了通用计算。
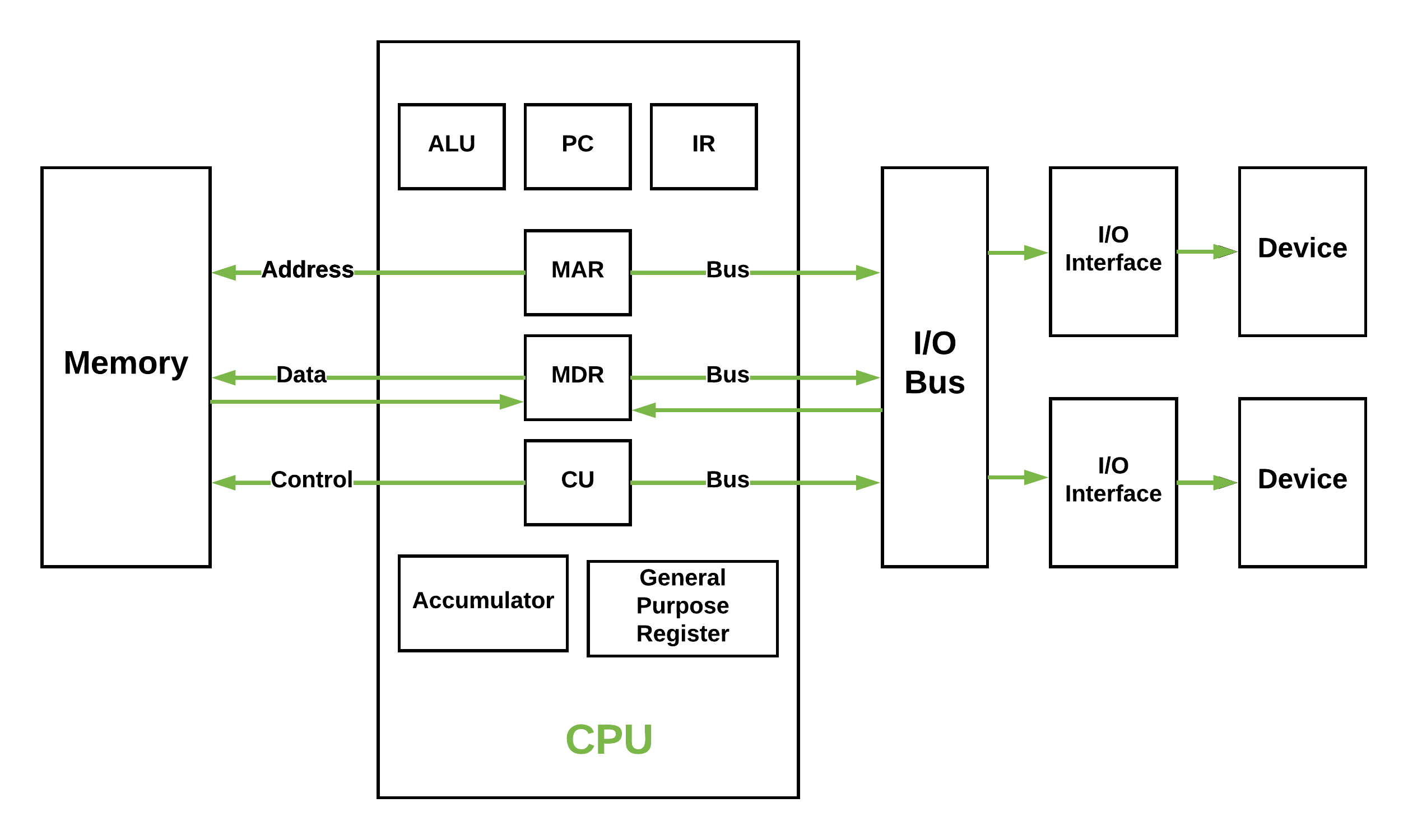
在一开始,这种创新的架构也的确给处理器产业带来了很大的提升。但在后续的发展中,无论我们采取何种措施来提升性能,都无法回避一个事实:指令一次只能执行一条,并且只能按顺序执行。这两个因素都限制了 CPU 的执行能力。与此同时,另一个问题也随之而生。
熟悉的读者应该知道,在当前的人工智能应用,搬运越来越多的数据是一个常态,但由于存储器的性能发展跟不上 CPU 的性能增长,导致 CPU 需要花费大量的时间等待存储器完成读写操作,从而降低了系统的整体性能,这就是所谓的“内存墙”问题。
为了解决这些问题,行业尝试了很多解决办法,当中以存算一体作为关注。
存算一体,走向台前
所谓存算一体(Processing-In-Memory, PIM 或 Compute-in-Memory, CIM),是一种新兴的非冯·诺依曼计算范式,作为解决“存储墙”问题的重要路径,其核心思想是在内存中执行某些计算任务,从而避免在处理单元和内存单元之间来回传输数据,避免数据移动所需的时间和能源成本是现代计算系统迄今为止面临的最大障碍。
回看这项技术的发展,从上世纪90年代到现在,已经进行了多个阶段的探索:
最初,以加州大学伯克利分校IRAM和伊利诺伊大学FlexRAM等为代表,他们基于DRAM/Flash等传统存储器进行“近存计算”尝试,但受限于工艺和集成度,未形成广泛影响;之后,伴随着新型存储器(如RRAM、PCM、STT-MRAM)兴起,具有非易失、高密度、可变阻特性,推动了模拟计算型PIM的发展,为AI推理等新兴场景提供了契机。
在此期间,除了三星、SK Hynix、Micron、英伟达、寒武纪、华为海思以及阿里达摩院等企业投入研发外。诸如斯坦福大学、MIT、ETH Zurich、清华大学、北京大学和中科院等科研机构也躬身其中。
如图所示,当前的主流PIM技术主要分为以下几种,他们都各具优势,面临的挑战也各不相同。

正是在这些企业和机构的多年投入下,自2017年以来,产业界开始推出原型产品。如三星的HBM-PIM和微米级阵列,这就是使PIM逐步从“论文走向芯片”。相关资料统计显示,星、SK海力士等巨头在 NAND Flash、ReRAM 等传统存储技术上依旧占据核心地位,其强大的 IDM和 Fab模式为高效存储和计算一体化提供了坚实基础。同时,类似Mythic 等新兴企业聚焦 ReRAM 和 MRAM 等前沿领域,推动了存算一体技术在高性能计算和边缘设备中的应用。来到国内,诸如知存、苹芯、亿铸、后摩智能和九天睿芯等企业也在这个领域各出奇招。
虽然存算一体欣欣向荣,矩阵乘法、卷积等操作已在CIM系统中广泛实现。但和冯诺依曼架构一样,这种架构也有它的天生瓶颈,那就是如何解决“排序”这个长期被视为“存算一体中的硬骨头”。
排序,作为人工智能系统中最常用、最耗时的基础操作之一,广泛存在于自然语言处理、信息检索、图神经网络、智能决策等人工智能相关领域中。
例如在智能驾驶场景中,车辆在高速公路等简单环境中,只需对周边几台车的行进路线进行排序就能判断是否会对自身安全产生影响,整个耗时可控制在毫秒级别,但在复杂的城市环境中风险来自周边的数百个乃至更多的各类交通参与者,排序的复杂程度和硬件延迟大幅提高;在抖音、小红书等平台大的规模检索与推荐系统中,用户点击、评分、相似度计算后,常需要对海量的候选内容进行快速排序,找出最相关项,排序性能直接影响系统的响应时间和可扩展性;
此外,在大语言模型训练、机器人路径规划、强化学习搜索等场景中,快速评估多个决策或行动的优劣并进行排序,也是必不可少而又极为费时的步骤。然而,在传统计算架构下,大规模的非线性排序难以在端侧或边缘设备高效完成,这一过程消耗大量时间与功耗,极大制约了具身智能、智能驾驶等新兴技术的发展与普及。
然而由于排序存在逻辑复杂、操作非线性、数据访问不规则,缺乏通用、高效的硬件排序原语等诸多障碍,目前国际主流的存算一体架构均无法解决大数据排序问题,这一难题成为了制约下一代人工智能计算硬件发展的前沿焦点与核心卡点问题。
正如北京大学集成电路学院人工智能研究院陶耀宇研究员所说,排序之所以成为CIM发展中迟迟未突破的难点,归根结底在于其“非结构化”“控制密集”的计算特性,这与当前以存内线性加速为核心的PIM设计理念天然存在张力。因此,若能突破排序在存算一体中的实现瓶颈,不仅是一项工程难题的攻克,更意味着CIM迈向通用智能计算平台的一大步。
于是,如何解决这个问题,就成了很多团队的关注点。国内团队也于近日带来了新的突破。
北京大学团队的突破
由北京大学集成电路学院杨玉超教授、人工智能研究院陶耀宇研究员组成的团队在近日宣布——在国际上首次实现了基于存算一体技术的高效排序硬件架构。随着这个突破性架构的面世,他们解决了传统计算架构面对复杂非线性排序问题时计算效率低下的瓶颈问题,为具身智能、大语言模型、智能驾驶、智慧交通、智慧城市等人工智能应用提供更高效算力支持。
值得一提的是,该成果也于近日在国际顶级学术期刊《自然∙电子》上发表。
据介绍,为了解决排序的问题,科研团队围绕“让数据就地排序”的第一性原理目标,在存算一体架构上攻克了多个核心技术难题,实现了排序速度与能效的数量级提升。具体而言,其主要突破包括以下几个方面:首先,开发了一套基于新型存内阵列结构的高并行比较机制;第二,开创性地引入了“忆阻器阵列”,实现了低延迟、多通路的硬件级并行排序电路设计;第三,在算子层面,优化了面向人工智能任务的算法-架构协同路径,同时兼容现有矩阵计算;第四,完全自主设计的器件-电路-系统级技术栈整合。
论文第一作者、北京大学集成电路学院博士生余连风介绍道,“排序的核心是比较运算,需要精准地实现‘条件判断+数据搬移’,在复杂的应用场景中,要对不同因素的优先级进行比较,因此排序的逻辑非常复杂。一般排序过程需要构建支持多级‘比较-选择’的比较器单元,而传统存算一体架构主要面向‘乘加’、‘累加’等操作,难以支持这样的复杂运算,我们的工作成功解决了这一难题,设计了一种‘无比较器’的存算一体排序架构。”
该团队总结说,此项技术的核心在于:
提出兼容现有存内矩阵计算的排序架构设计,实现了3.3至7.7倍的速度提升;
采用先进的忆阻器件,在能效方面实现了6.23倍至183.5倍的提升,显著降低系统运行成本;
支持多数据精度与多通道并行策略,打破传统排序模式下“精度固定”“难以并行”的限制;
设计实现从器件到架构的全链条方案,具备完全国产化、自主可控能力。
采用先进的忆阻器件,在能效方面实现了6.23倍至183.5倍的提升,显著降低系统运行成本;
支持多数据精度与多通道并行策略,打破传统排序模式下“精度固定”“难以并行”的限制;
设计实现从器件到架构的全链条方案,具备完全国产化、自主可控能力。
从团队提供的数据可以看到,据实测结果显示,该硬件方案在典型排序任务中提升速度超15倍,面积效率提升超过32倍,具备并行处理百万级数据元素排序任务的潜力,功耗仅为传统CPU或GPU处理器的1/10。在人工智能推理场景中,支持动态稀疏度下的推理响应速度可提升70%以上,特别适用于要求极高实时性的任务环境。
“正因为排序计算在人工智能中是高频、通用、基础且极难处理的一类操作,这一难题的突破意味着存算一体从‘适合特定应用’走向‘可支持更广泛的通用计算’,为人工智能相关任务构建了全链路的底层硬件架构支持。”论文通讯作者、北京大学人工智能研究院陶耀宇研究员补充说。
在该团队看来,存算一体超高性能排序加速架构的成功突破,不仅是一次架构创新的胜利,更是将科研成果转化为实际应用、服务国家重大战略需求的重要行动。该成果未来有望广泛应用于国产智能芯片、边缘AI设备、智能制造终端、智慧城市系统等关键领域,为我国在下一代AI技术与智能硬件竞争中提供坚实底座,也为构建安全、高效、自主可控的新一代智能算力体系提供了“加速引擎”。例如,在智慧交通场景中,系统有望在毫秒级内完成十万级事件优先级评估,为超大规模交通决策、应急响应调度等提供高效的实时算力支持。
“这一成果不仅是技术层面的突破,更是攻克了存算一体化排序加速的‘硬骨头’难题,在面向人工智能基础操作的硬件加速领域实现了突破,将为我国建设科技强国,实现高水平科技自立自强注入新算力。”该团队强调。
责任编辑:Ace
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号