四维破局!这家公司用一套方案撕开国产算力困局!
2026-06-15
15:33:22
来源: 清微智能
点击
随着"人工智能+"纵深推进,算力自主可控上升为国家战略。6月12日至13日,第八届北京智源大会在京举办,200余位全球顶尖学者与40余位企业掌门人齐聚。
世界模型、具身智能、AI自进化……前沿议题令人目不暇接,但议程深处,算力瓶颈始终是那道绕不开的必答题。
作为可重构计算架构的代表企业,清微智能携可重构超节点服务器、三维集成技术亮相展区。
华为、昆仑芯、寒武纪、摩尔线程……国产AI芯片核心力量悉数到场,北京作为"人工智能第一城"的产业厚度一览无遗。

清微智能在本次大会上提出"可用工程论"——以架构补工艺、以集成超制程、以系统聚算力、以自主创生态,四步环环相扣,让国产算力从"可运行"实实在在走向"经济性"。
一、以架构补工艺
在智算前沿论坛上,清微智能软件副总裁李彬的演讲开门见山:"模型越做越大,算力却跟不上了。"
 清微智能 李彬
清微智能 李彬
这句话背后,是一道横亘在国产芯片面前的结构性难题——先进制程受限,成熟制程如何撑起大模型时代?
清微的答案是:从计算架构上突破。传统架构芯片面临功耗墙、内存墙、通信墙层层限制,有效晶体管利用率不足40%。清微以可重构数据流引擎让计算单元根据数据流动按需重组,晶体管有效利用率一举突破70%,用成熟制程实现接近先进制程的有效算力。
清微的逻辑很明确:不依赖于制程工艺升级的限制,用架构重新定义效率。李彬介绍,该方案已在电力、政务、EDA、电信四大关键行业完成规模化部署。
二、以集成超制程
如果"架构补工艺"解决的是计算效率的问题,那么"集成超制程"瞄准的则是“内存墙”。展区现场,清微的三维集成芯片技术吸引了众多与会者驻足。
这是清微即将问世的下一代AI芯片,采用3.5D异构堆叠与Chiplet架构,让可重构计算芯粒与DRAM存储芯粒实现了三维垂直堆叠——不再是传统2D平面上的"单车道",而是立体贯通的"四车道"。
 清微智能展台前人流如织
清微智能展台前人流如织
突破的关键在于将距离缩到最短——信号传输从毫米级压到微米级,访存带宽比传统HBM高出数倍,算力引擎可以持续满负荷运转,使得千亿参数大模型参数搬运的延迟大幅下降。
这套技术路径是清微面向下一代AI芯片的核心储备,也是"集成超制程"从理念走向工程的实质性一步。
三、以系统聚算力
当数千颗芯片组成集群,真正的考验便从“算力够不够”转向“互联快不快”。
清微率先交出的答卷,是一款已经落地的可重构智算超节点。它将4096颗可重构计算芯片以访存语义进行基于Mesh拓扑的点对点通信,并且不依赖于任何单独的交换芯片或交换机。该超节点算力突破每秒500千万亿次,互联成本较国外同类方案直降90%。
今年3月,该成果入选2026中关村论坛重大科技成果,并在北京市某算力场项目中正式上线。清微4K超节点服务器已成为首个全域就绪、全程贯通的国产算力解决方案。
 清微超节点产品此前登上央视《新闻联播》
清微超节点产品此前登上央视《新闻联播》
从千卡集群的工程验证起步,到十余个省份万卡级智算中心的规模化部署,清微正把"系统聚算力"从一句理念,锤炼为一张可随时调用的国产算力网络。
四、以自主创生态
如果说前三步解决的是"算得快"的问题,那么第四步回答的是"容易用"的命题。回看清微与智源研究院的合作历程,是一条从技术适配到生态协同、再到标准定义的持续深化之路。
在软件层面,清微是行业内少数实现 FlagOS 全部核心组件全栈兼容的企业,适配规模在非GPU架构中与华为昇腾并列前二。这意味着,基于 FlagOS 开发的 AI 应用,可以在清微芯片上无缝运行。
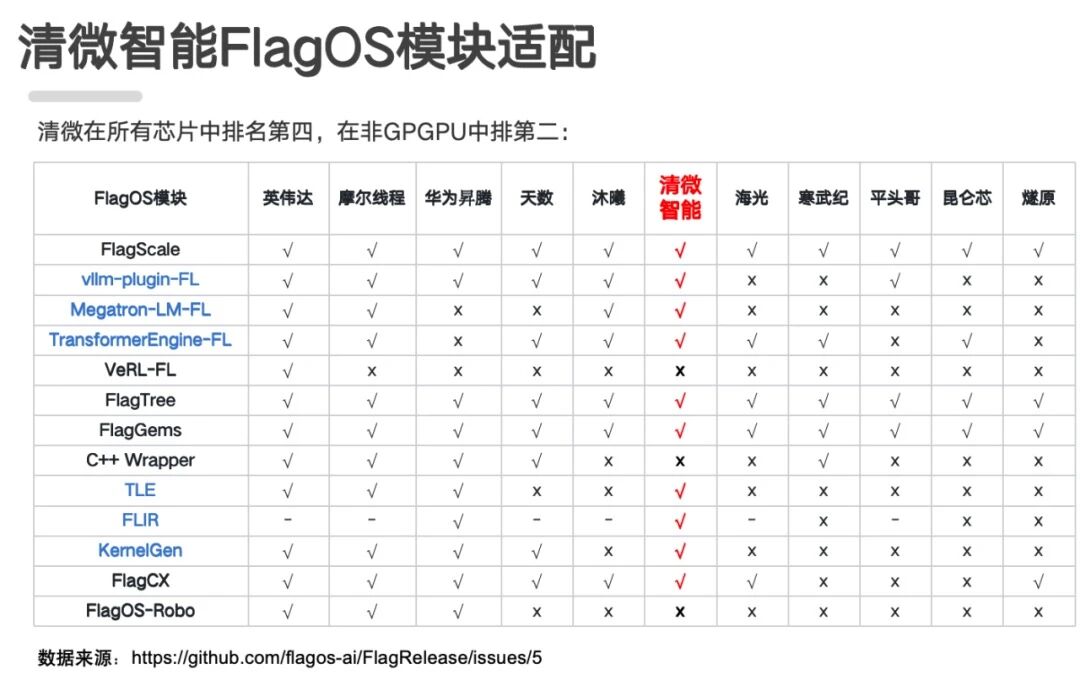 清微智能与FlagOS的技术适配
清微智能与FlagOS的技术适配
今年4月底,包括清微智能在内的10家国产AI芯片,基于FlagOS首次实现了千亿大模型 DeepSeekV4的DAY0适配,并通过FlagRelease发布了模型推理镜像。
特别值得一提的是,本次适配工作主要由生态开发者主导完成,不再是由芯片厂商主导。这进一步体现了国产创新架构和国产软件生态“一次编写,多芯部署”这一双向奔赴的用户价值。
从架构突破到生态协同,清微不仅走出了一条新的技术路径,更是对国家算力自主可控战略提供了坚实算力底座。
在全国一体化算力网加速织就的当下,清微以可重构架构为基座、以全栈软件生态为纽带,构建起从单点芯片到万卡集群、从底层硬件到上层生态的全链条国产化能力,为国产算力从“可用”迈向“好用”提供了可复制、可推广的清微方案。
世界模型、具身智能、AI自进化……前沿议题令人目不暇接,但议程深处,算力瓶颈始终是那道绕不开的必答题。
作为可重构计算架构的代表企业,清微智能携可重构超节点服务器、三维集成技术亮相展区。
华为、昆仑芯、寒武纪、摩尔线程……国产AI芯片核心力量悉数到场,北京作为"人工智能第一城"的产业厚度一览无遗。
清微智能在本次大会上提出"可用工程论"——以架构补工艺、以集成超制程、以系统聚算力、以自主创生态,四步环环相扣,让国产算力从"可运行"实实在在走向"经济性"。
一、以架构补工艺
在智算前沿论坛上,清微智能软件副总裁李彬的演讲开门见山:"模型越做越大,算力却跟不上了。"
清微智能 李彬这句话背后,是一道横亘在国产芯片面前的结构性难题——先进制程受限,成熟制程如何撑起大模型时代?
清微的答案是:从计算架构上突破。传统架构芯片面临功耗墙、内存墙、通信墙层层限制,有效晶体管利用率不足40%。清微以可重构数据流引擎让计算单元根据数据流动按需重组,晶体管有效利用率一举突破70%,用成熟制程实现接近先进制程的有效算力。
清微的逻辑很明确:不依赖于制程工艺升级的限制,用架构重新定义效率。李彬介绍,该方案已在电力、政务、EDA、电信四大关键行业完成规模化部署。
二、以集成超制程
如果"架构补工艺"解决的是计算效率的问题,那么"集成超制程"瞄准的则是“内存墙”。展区现场,清微的三维集成芯片技术吸引了众多与会者驻足。
这是清微即将问世的下一代AI芯片,采用3.5D异构堆叠与Chiplet架构,让可重构计算芯粒与DRAM存储芯粒实现了三维垂直堆叠——不再是传统2D平面上的"单车道",而是立体贯通的"四车道"。
清微智能展台前人流如织突破的关键在于将距离缩到最短——信号传输从毫米级压到微米级,访存带宽比传统HBM高出数倍,算力引擎可以持续满负荷运转,使得千亿参数大模型参数搬运的延迟大幅下降。
这套技术路径是清微面向下一代AI芯片的核心储备,也是"集成超制程"从理念走向工程的实质性一步。
三、以系统聚算力
当数千颗芯片组成集群,真正的考验便从“算力够不够”转向“互联快不快”。
清微率先交出的答卷,是一款已经落地的可重构智算超节点。它将4096颗可重构计算芯片以访存语义进行基于Mesh拓扑的点对点通信,并且不依赖于任何单独的交换芯片或交换机。该超节点算力突破每秒500千万亿次,互联成本较国外同类方案直降90%。
今年3月,该成果入选2026中关村论坛重大科技成果,并在北京市某算力场项目中正式上线。清微4K超节点服务器已成为首个全域就绪、全程贯通的国产算力解决方案。
清微超节点产品此前登上央视《新闻联播》从千卡集群的工程验证起步,到十余个省份万卡级智算中心的规模化部署,清微正把"系统聚算力"从一句理念,锤炼为一张可随时调用的国产算力网络。
四、以自主创生态
如果说前三步解决的是"算得快"的问题,那么第四步回答的是"容易用"的命题。回看清微与智源研究院的合作历程,是一条从技术适配到生态协同、再到标准定义的持续深化之路。
在软件层面,清微是行业内少数实现 FlagOS 全部核心组件全栈兼容的企业,适配规模在非GPU架构中与华为昇腾并列前二。这意味着,基于 FlagOS 开发的 AI 应用,可以在清微芯片上无缝运行。
清微智能与FlagOS的技术适配今年4月底,包括清微智能在内的10家国产AI芯片,基于FlagOS首次实现了千亿大模型 DeepSeekV4的DAY0适配,并通过FlagRelease发布了模型推理镜像。
特别值得一提的是,本次适配工作主要由生态开发者主导完成,不再是由芯片厂商主导。这进一步体现了国产创新架构和国产软件生态“一次编写,多芯部署”这一双向奔赴的用户价值。
从架构突破到生态协同,清微不仅走出了一条新的技术路径,更是对国家算力自主可控战略提供了坚实算力底座。
在全国一体化算力网加速织就的当下,清微以可重构架构为基座、以全栈软件生态为纽带,构建起从单点芯片到万卡集群、从底层硬件到上层生态的全链条国产化能力,为国产算力从“可用”迈向“好用”提供了可复制、可推广的清微方案。
责任编辑:SemiInsights





-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号