算力需求井喷,英特尔至强6如何当好胜负手?
2025-06-25
14:00:04
来源: 杜芹
点击
AI大模型正在重构企业的算力版图。从云端部署的快速试水,到企业用户对数据主权、安全边界和TCO的深度考量,越来越多的组织开始意识到:AI基础设施不只是“多几块GPU”那么简单。尤其在模型规模持续扩张、上下文窗口拉长、推理并发增长的现实面前,传统以GPU为核心的算力架构正面临边际效能递减的挑战。
与此同时,长期被低估的CPU价值正在回归。
大模型负载,不仅需要GPU算力,也需要CPU算力
“在一个完整的AI业务架构中,CPU和GPU承担着不同角色。”火山引擎云基础产品经理负责人李越渊在6月11日的2025火山引擎春季原动力大会上指出,除了大家熟知的大语言模型的训练和推理,模型快速迭代还涉及大量的前置数据采集、数据合成和数据清洗、标注等工作。模型效果提升离不开RAG,其中还包含embedding、reranking 和搜索等多个步骤。这些围绕大模型的负载,不仅需要大量的GPU算力,同时也需要CPU的算力协同配合,这种分工模式要求企业必须同步升级两类算力资源,以满足端到端的AI业务需求。
当前大语言模型的迅速迭代发展也对处理器带来了不少挑战,据英特尔技术专家的介绍,主要有四点:1)GPU计算效率低;2)CPU 利用率低;3)更高的数据移动带宽需求;4)GPU显存容量限制。
面对这四大挑战,英特尔见招拆招,设计了多种基于异构的解决方案:
1)数据预处理流水线的CPU利用。将CPU主动引入训练与推理流水线,尤其是在latent特征预计算等任务中,能有效降低对GPU的依赖(测试结果表明,整体训练性价比可提升约10%);
2)投机执行的CPU+GPU方案。至强6处理器专为这一类轻量模型的运行进行了优化。借助强大的吞吐能力,小模型能在低延迟场景下快速响应,从而将更多宝贵的GPU算力释放给主模型。
3)KVCache QAT压缩优化。KV Cache是生成任务中的关键资源,尤其在多轮对话或长上下文任务中,占用显存迅速膨胀。例如一个日活1万的对话系统,每天可能产生4TB以上的KV数据。为此,英特尔引入了QAT硬件加速压缩方案,结合冷热数据分级迁移,将KV从GPU逐步下沉至CPU及磁盘,同时压缩体积、减少加载延迟。在实际部署中,如Qwen2.5-14B模型的对话任务,通过QAT加速压缩后,首词延迟大幅下降,用户响应体验显著提升。
4)稀疏感知的MoE CPU卸载。多专家模型(MoE)如DeepSeek-671B,其激活路径天然稀疏,仅需调用少数专家模块,极适合进行计算卸载优化。通过热度感知调度机制,将高频专家部署至GPU,低频专家迁移至CPU,显存瓶颈被显著缓解。在实测场景中,使用8卡GPU服务器推理DeepSeek-R1模型,原本最大并发仅11人,通过引入稀疏感知卸载策略,并发数提升至27人,整体吞吐提升2.45倍。
随着大模型的普及,AI算力体系正从“GPU为中心”转向“多设备协同”的异构计算架构。CPU不再只是辅助角色,而是在投机执行、预处理、专家分担等关键路径上承担起核心任务。面对带宽瓶颈、显存压力、低效资源利用等现实问题,只有通过系统级的异构优化,才能支撑未来更大规模、更复杂模型的部署与服务。依托至强6处理器,英特尔等厂商正在推动这种变革,让每一瓦功耗、每一份算力都物尽其用。
至强6,AI时代的“胜负手”
2024年,英特尔正式发布了全新的至强6处理器,并在今年上半年陆续推出该系列的完整家族产品。至强6处理器不是单点突破的产品,而是英特尔在芯片设计、系统优化、生态协同等多方面集大成的代表作。这一代至强处理器的目标很明确:应对数据中心正在发生的巨大变化,满足客户业务高速增长下的多样化计算需求。
为何说至强6不是单点突破的产品?
首先在架构层面,至强6大胆采用模块化设计思路,将I/O模块与计算模块解耦,显著简化了系统验证流程。更重要的是,这种设计不仅让英特尔受益,也让整个生态圈——包括合作伙伴和客户——在开发和部署阶段节省了大量资源与时间。同时,计算模块也实现了灵活扩展,可轻松覆盖从低核心数到高核心数的不同应用场景。BIOS框架也同步升级,为性能核与能效核的动态调度提供了强大支撑。

其次,至强6处理器在性能上实现了飞跃:最多288个物理核心,内存通道从8条提升至12条,DDR5内存速率最高达6400MT/s,再叠加MRDIMM技术,整体内存带宽相较上一代提升了2.3倍,强力支撑AI、搜索等大带宽应用。
I/O方面,PCIe带宽提升至原来的1.2倍,跨插槽通信带宽提升1.8倍,并率先支持CXL 2.0协议,为内存扩展和共享打开新可能,帮助行业在下一阶段的系统设计上更进一步。
再者,作为近年来英特尔重点打造的差异化能力,至强6内置了一系列硬件加速模块:包括用于加速压缩/解压的QAT、数据处理加速的DSA、内存压缩的IAA、负载均衡的DLB等。其中一个QAT引擎可替代约6.8个CPU核心的计算压力,整合4个QAT模块后,相当于释放出多达32个核心的计算资源。至于AI场景,至强6也不示弱——内建的AMX加速器大幅提升了CPU执行AI任务的效率。
最后,在通用计算、Web服务和AI等关键场景中,至强6900系列的性能相较上一代提升超过2倍,同时能效比提升1.4倍。在保持相同功耗下,性能依旧能提升40%以上。如果核心数固定,也能实现约20%的性能增益。尤为值得一提的是,在云计算场景下,至强6实现了2倍的核心密度、60%的性能能效提升,并预计可带来30%的TCO节省,性价比极为可观。
综合来看,至强6产品家族丰富,规格全面进阶。具体来看,至强6700/6500系列支持8通道DDR5与8000MT/s MRDIMM内存,最多支持144个能效核或86个性能核,PCIe通道多达136个;而6900系列则进一步扩展至12通道内存,支持高达8800MT/s的带宽,PCIe通道数为96个,核心密度更是刷新纪录——最高可支持288个能效核或128个性能核。此外,至强6产品线还涵盖32核、48核、64核、72核等多个规格,并支持与多种GPU组合,充分满足客户在AI推理、视频处理和大规模分布式部署中的多元化需求。

“芯云协同”,至强6让算力普惠各行各业
英特尔中国互联网行业总监李志辉指出:“过去三年,AI极大地推动了整个产业重大的数字化进程,对整个产业格局的改变产生了深远影响。在算力需求井喷的现实情况下,如何让算力更高效、更普惠地服务于千行百业,成为重要核心。”
英特尔认为,"芯云协同"成为关键答案--芯片与云的深度融合,正在重新定义算力的生产、调度与使用方式。芯云协同,不是只喊喊口号。此前英特尔与火山共同发布了火山引擎第四代云实例g4il,双方长期以来的深度合作也为芯云协同写下了比较生动的注脚。
在本次大会上,搭载最新的英特尔至强6性能核处理器(GNR-AP),火山引擎推出第4代ECS实例家族。ECS实例高度协同CPU/GPU,还配备了火山引擎自研 DPU 以及自研服务器,无论在通用互联网场景、算力密集以及IO密集场景,性能相比上一代都实现大了幅提升。

第四代实例的网络与存储能力也进行了全面升级,整机网络和存储带宽最大提升100%,IOPS和PPS提升30%以上,CPU频率最高提升了20%。此外,通过双单路创新架构,实例的稳定性进一步增强,有效降低故障影响范围;在功能方面,新增支持Jumbo Frame,机密计算TDX的能力,并支持新型吞吐型SSD云盘提升带宽密度,全面拓展新应用场景。
除了上述通用场景的性能提升,基于最新四代实例,火山引擎联合英特尔在RAG应用上进行了深度优化。在大语言模型的应用体系中,RAG(Retrieval-Augmented Generation)已成为提升输出质量的核心技术。其基本原理是通过向量数据库检索相关信息,再交由语言模型融合生成,从而增强模型的知识覆盖与实时性。针对RAG应用的四个主要环节,包括上传文档处理、Embedding向量化、向量数据库检索和Reranking排序,通过充分利用g4il实例中的AMX矩阵运算加速器,任务耗时最多可减少90%,有效助力了RAG应用全链路提速。
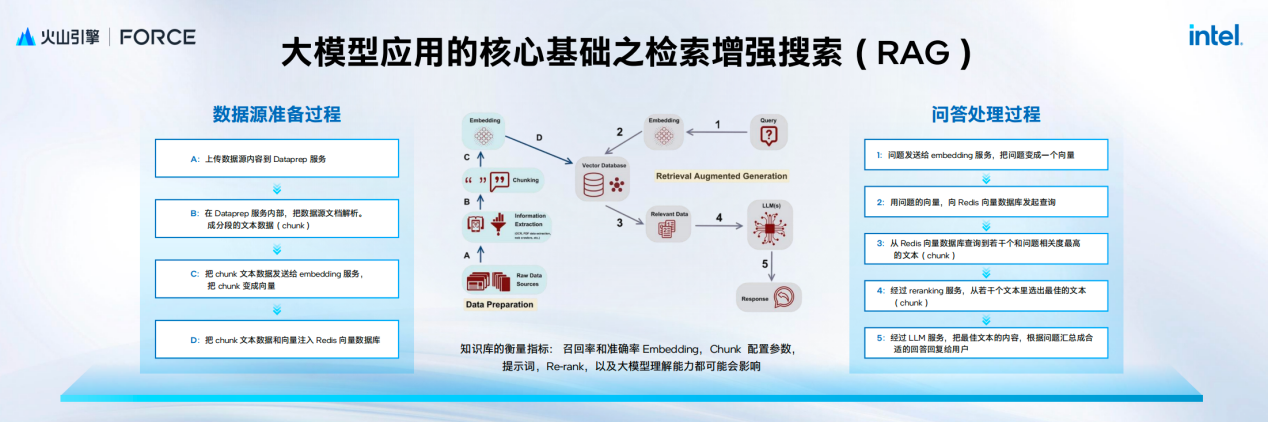
随着互联网用户规模不断扩大,搜索推荐场景的数据量呈指数级增长,导致对算力需求显著增加。面对这一挑战,火山引擎与英特尔团队进行了深入研究,通过AMX优化,CPU的推理性能实现了质的飞跃。优化后,CPU实例吞吐能力提升114%,显著提升模型推理效率。
以“高性价比一体机”推动大模型本地化部署
在大语言模型大规模落地的当下,火山引擎、字节跳动等企业的快速动作已经为行业验证了其商业潜力。而在云端之外,一个正在悄然兴起的趋势值得关注——企业级用户正在寻求“本地可控、性能可用、成本可接受”的AI平台。
对许多企业而言,业务数据构成其核心资产。尤其是在金融、医疗、制造等行业,数据上云意味着风险和合规难题,而本地部署成为优选路径。然而,企业也同时面临另一个现实:大模型能力持续迭代,若盲目本地化,容易陷入算力落后、模型过时的技术陷阱。
在这一背景下,基于英特尔锐炫GPU,英特尔打造了高性价的智算一体机,试图打通大模型本地部署的“最后一公里”。该企业级AI一体机方案主要包括两类架构:
l 纯本地部署:全部模型、软件栈及服务运行在企业内部,数据不出域,适用于隐私、安全要求极高的场景。基于单机或多机集群架构,具备完整的软件封装与性能优化。
l 云边协同部署:结合云上模型能力(如豆包1.6/1.7)与本地业务逻辑处理,将大模型推理任务部分外包,敏感数据处理保留在本地,有效提升灵活性与性价比。

在这两类架构下,企业可以基于业务诉求灵活选择。例如,将大模型主干部署在云端,Embedding、Rerank等任务本地完成;或使用开源模型(如DeepSeek、千问等)在本地独立运行,从而实现高性价比推理服务。
可以看出,在硬件层面,英特尔选择了一条不同寻常的路径——以消费级GPU为起点,打造企业AI计算平台。第一代锐炫A770(16GB显存)已可运行主流模型,而最新发布的锐炫Pro B60(24GB显存)更是针对AI推理等场景进行专门设计。
显存的扩容,正是为了应对企业AI两大核心瓶颈:1)更长的上下文窗口:支持32K、甚至128K token上下文,已成为企业知识问答场景的刚需,对显存的依赖显著提升。2)更高的并发能力:每个并发任务都需维持完整KV Cache,显存资源直接决定并发规模。
在本地运维方面,英特尔一体机解决方案集成了以Grafana为核心的监测系统,支持CPU、GPU及平台资源的完整可观测性,并提供Prometheus或数据接口,便于集成进企业既有运维体系。
此外,通过EAP(Edge AI Platform)这一套完整的软件封装体系,企业现有模型可以几乎“零改造”平滑迁移至英特尔平台,享受其在成本与可维护性上的优势。
英特尔以锐炫GPU+至强CPU的组合,辅以开源模型生态、异构部署能力及完整的软件工具链,为企业客户提供了一条“可负担、可控、可持续”的本地化路径。这背后不仅是对硬件的深耕,更是对企业AI落地节奏与形态的精准判断。
写在最后
AI时代不是某项技术的胜出,而是算力、架构、模型与生态之间的深度协作。而在这场协作中,英特尔携手生态合作伙伴,以“芯云协同”为路径,共同构建开放、共赢的AI计算新格局,让AI算力从“云上专属”走向“企业普惠”。
责任编辑:admin
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号