8-12核锐龙AI嵌入式P100发布,AMD处理器再进化
2026-03-10
09:56:17
来源: 互联网
点击
在大模型训练主导 AI 市场多年后,产业重心正加速向场景落地转移。近期风靡全球的 OpenClaw(养龙虾) 便是其中的典型。在此之前,包括自动驾驶、智能工业及机器人等领域也正在人工智能的推动下发生深刻变革。自去年以来,“物理 AI”(Physical AI) 的兴起,更是进一步推动人工智能从数字世界深度渗透进物理现实。
这种从“云端逻辑”向“边缘执行”的范式转移,对算力的实时性与异构性提出了更高要求。
作为该领域极少数具备全栈算力支撑的供应商,AMD 近日带来了全新的锐龙 AI 嵌入式处理器P100 系列。通过领先的异构计算架构,该系列产品为工业边缘与物理 AI 解决方案提供了可扩展的高效算力,成为赋能未来智能感知与实时行动的关键底座。
锐龙AI嵌入式P100,为边缘而生
在今年年初发布P100 系列处理器的时候,AMD就曾表示,该系列产品能够为车载体验和工业自动化提供强劲的支持。
诚然,如AMD所说,一方面,在无论是汽车、机器人,还是智能工厂等应用中,都必须要有可靠性和低时延,并且不依赖于云的底层算力支撑;另一方面,包括传感器融合、可视化、人工智能的推断和控制逻辑在内的各种各样负载都需要并行工作,这就不但需要对解决方案的封装尺寸提出了更高的要求,还要求提供方便的算力扩展;此外,从汽车到机器人,多屏幕支持已经成为嵌入式解决方案的刚需。
锐龙AI嵌入式P100系列,为嵌入式市场提供更强劲的支持。据介绍,这些处理器集成了高性能的“Zen 5”核心架构,可实现可扩展的x86性能和确定性控制;集成了RDNA 3.5 GPU,用于实时可视化和图形处理;集成了XDNA 2 NPU,用于低延迟、低功耗的AI加速。与此同时,该系列处理器还提供了一致的开发环境,其统一的软件栈涵盖 CPU、GPU 和 NPU。在运行时层,开发人员可受益于优化的 CPU 库、开放标准的 GPU API,以及通过锐龙 AI 软件实现的原生 XDNA 架构 AI 运行时。
从配置上看,今年一月份发布的P100系列能够完美应对上述需求。
然而,正如大家所见,AI正在以前所未有的速度进化,这就对底层芯片供应商带来了新的挑战。AMD 锐龙嵌入式处理器高级产品市场经理Ioseph Martinez在日前的一个分享中也指出,包括智能自动化、人工智能赋能的终端以及大规模物理AI的落地,正在给行业提出新的需求。
例如,面对人工智能赋能的终端,我们需要在诸如成像、诊断、临床推理等复杂应用中利用人工智能增强:因应大规模物理AI落地的趋势,我们需要紧凑型系统实现完全自主运行,释放各行业的效率潜力。
据笔者观察,随着物理 AI 对算力的需求已从单纯的“云端推理”转向了具备实时反馈能力的边缘异构协同:它不仅要求单芯片集成高算力加速器以满足复杂多模态大模型需求。面对不同的负载要求,物理AI也希望能够有异构集成的解决方案来高效处理。
有见及此,AMD扩展了锐龙 AI 嵌入式处理器产品组合,并于近日推出了新款 P100 系列处理器,以更强的算力,为工业与 AI 边缘解决方案提供可靠的支持。
因应需求,再度进化
从AMD的介绍我们得知,和与此前发布的采用相同紧凑型球栅阵列(BGA)封装的 P100 系列处理器一样,新的P100系列同样采用了Zen 5 CPU、XDNA 2 NPU和 RDNA 3.5 GPU的异构集成方案,把所有功能均融于一颗芯片中。但和之前的发布产品不同之处在于,新款处理器可提供最高 2 倍的 CPU 核心数量、最高 8 倍的图形处理单元(GPU)算力,且系统级每秒万亿次运算(TOPS)性能预计提升 36%。
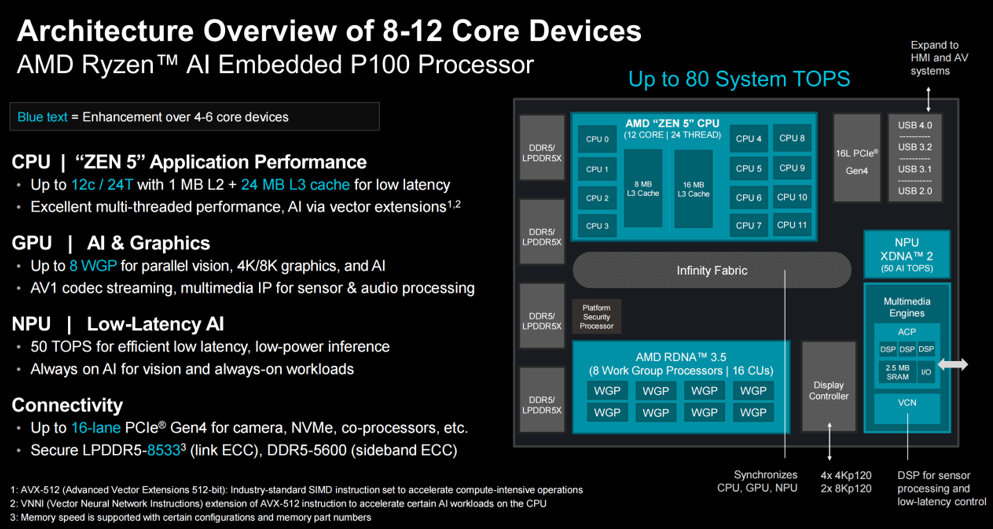
资料显示,此前发布的 P100 系列处理器配备 4-6 颗核心,但新发布的系列涵盖了8到12个CPU核心。与上一代 AMD Ryzen Embedded 8000 APU 相比,其多线程性能提升高达 39%。除此以外,Zen 5核心还提供了隔离能力和充足的性能裕量,可以在单个平台上以确定性的多任务方式整合多个关键工作负载。
来到GPU方面,新发布的P100系列处理器最高拥有8个GPU,能应对更繁重的工作负载。得益于这些配置,使其在处理多4K/8K p120渲染、多叠加人机界面和低延迟视频合成时游刃有余。其集成的AV1解码器和AMD视频引擎,同时带来了高保真、低延迟的流媒体播放和流畅的播放体验。
如上所述,和此前发布的P100系列一样,AMD在新发布的系列处理器上依然集成了NPU。在AMD看来,这个由“iGPU+NPU”组成的端到端AI加速器能够根据需要将工作负载分配给合适的引擎,更好地平衡芯片的功耗和性能。
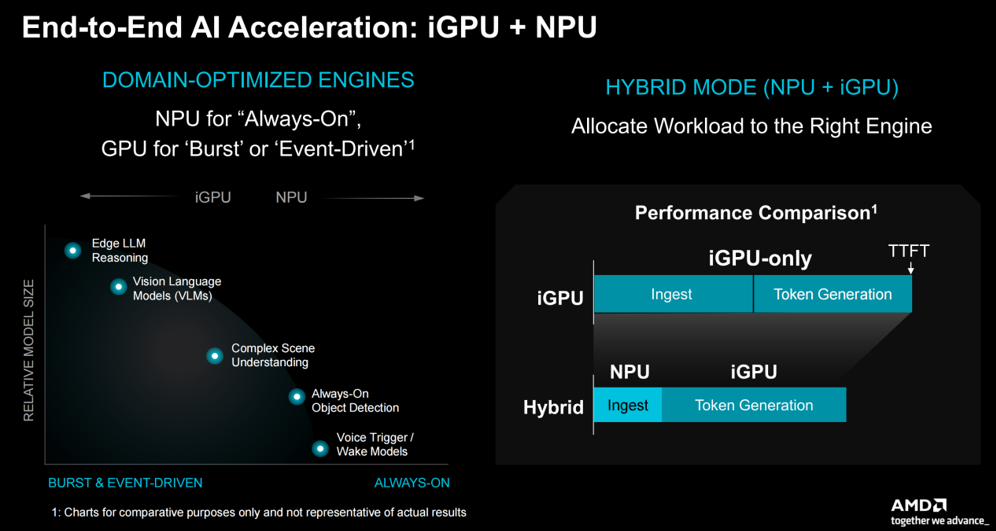
在这样配置支持下,新推出的P100最高提升 2.1 倍的系统级总TOPS—— 80 TOPS 的系统级算力,与现有 P100 系列相比,新款处理器提供了卓越的 AI 每瓦性能,并可支持近 2 倍数量的虚拟机以及更大规模的大语言模型(例如 Llama 3.2-Vision 11B),从而推动更先进的 AI 与混合型工作负载。
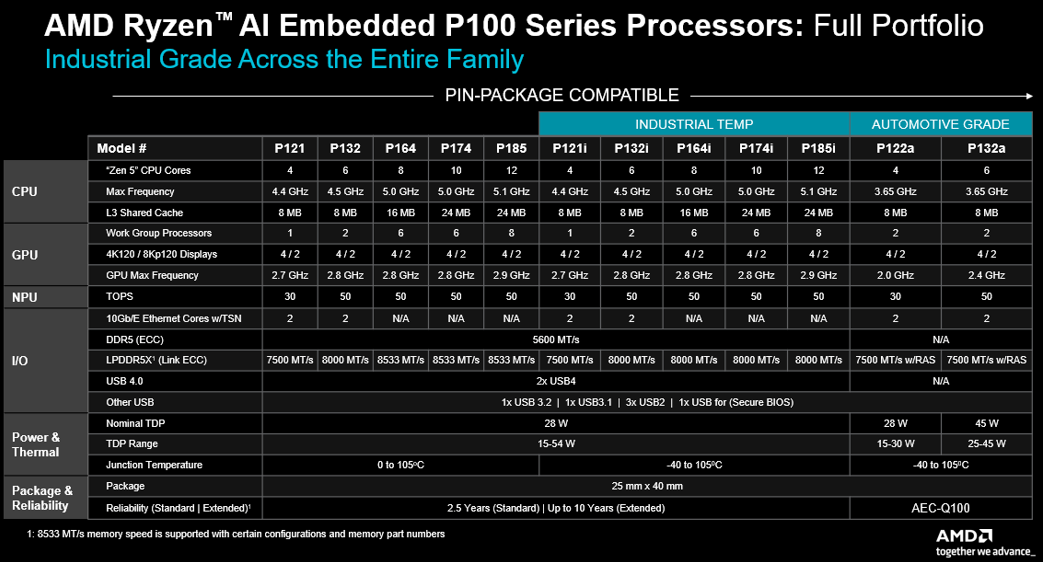
AMD强调,紧密集成的 CPU、GPU 和 NPU 架构能在混合工作负载下实现高效的工作负载分配,并确保可预测的时延;同时,使用熟悉的框架和软件栈有助于在广泛的用例中简化和精简开发与部署。这种集成水平还能在无需额外外部组件的情况下实现先进的计算与图形处理能力,使 OEM 厂商和系统集成商可以更轻松地设计可扩展的平台。
由此可见,除了性能优越的硬件外,软件也是一个产品能否征服客户的另一个关键指标。这也恰好也正是AMD一直深耕的方向。AMD也表示,得益于对 AMD ROCm 开放软件生态系统的支持,公司为嵌入式应用带来了一套业经验证的开源 AI 软件栈。开发人员可以在依赖开源编译器、运行时和库的同时运行标准 AI 框架,并且无需重写代码即可即时访问适用于嵌入式的模型。在编程层面,ROCm 软件采用开源的 HIP (Heterogeneous-computing Interface for Portability),将 GPU 编程从硬件中解耦,消除了软件栈和硬件之间的供应商锁定。

“通过提供跨异构引擎的优化 AI 技术栈,AMD能针对每个引擎优化的软件栈,以实现最佳性能和功耗;同时,该软件栈还支持通用开源框架,可灵活地将工作负载定向到特定引擎;此外,这个软件栈的模型支持涵盖从基础模型到自定义模型,从视觉(CNN)到推理(LLM、VLA)。”AMD补充说。
值得一提的,AMD 还为工业领域的混合关键型应用提供了一个封装式、垂直整合的虚拟参考堆栈。该堆栈基于 Xen 虚拟管理程序构建,可在隔离域中运行 Linux®、 Windows®、Ubuntu® 和 RTOS 环境,从而实现安全性、实时性能与灵活性。最终形成一个可扩展的、开放的架构,为下一代嵌入式系统简化设计并加速开发。
写在最后
据AMD介绍,在这些软硬件支持下,公司新推出的P100系列处理器可支持从视觉到控制到推理的实时 AI、提供先进的图形处理能力,同时还支持工业温度范围(−40℃ 至 105℃)、7×24 小时连续运行以及 10 年产品生命周期,这让其能够在从智慧工厂到工业 PC再到自主机器人和医学成像设备等应用中发挥重要的作用。

AMD进一步指出,新款 x86 嵌入式处理器针对下一代工业和更广泛的边缘 AI 用例进行了优化。这些用例包括:
用于工业 PC 的智能机器视觉:新款处理器能实现将可编程逻辑控制器(PLC)、机器视觉与人机界面(HMI)整合到同一台工业 PC,同时为实时监测与处理优化提供所需的 CPU 性能。集成的 GPU 和 NPU 可加速多路摄像头视觉与丰富的 HMI 仪表板,并支持利用 DeepSORT、RAFT-Stereo、CenterPoint、GDR-Net、PaDiM 和 Llama 3.2-Vision 等模型的低时延异常检测。
用于自主运行的物理 AI:针对移动机器人,该处理器可在 CPU 上管理导航、运动控制与路径规划,而 GPU 则处理多路摄像头数据,实现空间感知、Visual SLAM(视觉 SLAM) 以及视觉-语言-动作(vision-language-action, VLA)模型等高级 AI 工作负载。CPU 与 GPU 之间的统一内存实现了低时延,从而提升了响应速度。NPU 可提供始终在线的低功耗推理,支持基于 YOLOv12 和 MobileSAM 等模型的目标检测与场景理解。
3D 医学成像与临床智能:利用 U-Net、nnU-Net 和 MONAI 等模型,该处理器可在边缘端支持超声、内窥镜、组织分类以及肿瘤检测等 3D 成像。处理器可借助 MedSigLIP 加速从成像到报告的工作流程,并支持通过 Med-PaLM2 实现临床推理与问答能力。医疗领域原始设备制造商(OEM)能在可扩展的长生命周期 x86 嵌入式平台上整合成像、AI 分析与报告功能。
综合来看,8-12核AMD锐龙AI嵌入式 P100 系列并非简单的参数升级,而是针对边缘侧混合工作负载的一次精准提升 。它通过集成 Zen 5 核心的高效逻辑处理、RDNA 3.5 的实时可视化以及 XDNA 2 的低功耗推理,真正解决了物理 AI 在复杂场景下的算力冗余与时延痛点。
随着 2026 年下半年该系列产品的全面量产,嵌入式 AI 市场将迎来一次生产力的集体跃迁。对于那些追求高性能、长生命周期以及开源生态的 OEM 厂商而言,P100 无疑是目前构建下一代智能边缘解决方案的最优解之一。
这种从“云端逻辑”向“边缘执行”的范式转移,对算力的实时性与异构性提出了更高要求。
作为该领域极少数具备全栈算力支撑的供应商,AMD 近日带来了全新的锐龙 AI 嵌入式处理器P100 系列。通过领先的异构计算架构,该系列产品为工业边缘与物理 AI 解决方案提供了可扩展的高效算力,成为赋能未来智能感知与实时行动的关键底座。
锐龙AI嵌入式P100,为边缘而生
在今年年初发布P100 系列处理器的时候,AMD就曾表示,该系列产品能够为车载体验和工业自动化提供强劲的支持。
诚然,如AMD所说,一方面,在无论是汽车、机器人,还是智能工厂等应用中,都必须要有可靠性和低时延,并且不依赖于云的底层算力支撑;另一方面,包括传感器融合、可视化、人工智能的推断和控制逻辑在内的各种各样负载都需要并行工作,这就不但需要对解决方案的封装尺寸提出了更高的要求,还要求提供方便的算力扩展;此外,从汽车到机器人,多屏幕支持已经成为嵌入式解决方案的刚需。
锐龙AI嵌入式P100系列,为嵌入式市场提供更强劲的支持。据介绍,这些处理器集成了高性能的“Zen 5”核心架构,可实现可扩展的x86性能和确定性控制;集成了RDNA 3.5 GPU,用于实时可视化和图形处理;集成了XDNA 2 NPU,用于低延迟、低功耗的AI加速。与此同时,该系列处理器还提供了一致的开发环境,其统一的软件栈涵盖 CPU、GPU 和 NPU。在运行时层,开发人员可受益于优化的 CPU 库、开放标准的 GPU API,以及通过锐龙 AI 软件实现的原生 XDNA 架构 AI 运行时。
从配置上看,今年一月份发布的P100系列能够完美应对上述需求。
然而,正如大家所见,AI正在以前所未有的速度进化,这就对底层芯片供应商带来了新的挑战。AMD 锐龙嵌入式处理器高级产品市场经理Ioseph Martinez在日前的一个分享中也指出,包括智能自动化、人工智能赋能的终端以及大规模物理AI的落地,正在给行业提出新的需求。
例如,面对人工智能赋能的终端,我们需要在诸如成像、诊断、临床推理等复杂应用中利用人工智能增强:因应大规模物理AI落地的趋势,我们需要紧凑型系统实现完全自主运行,释放各行业的效率潜力。
据笔者观察,随着物理 AI 对算力的需求已从单纯的“云端推理”转向了具备实时反馈能力的边缘异构协同:它不仅要求单芯片集成高算力加速器以满足复杂多模态大模型需求。面对不同的负载要求,物理AI也希望能够有异构集成的解决方案来高效处理。
有见及此,AMD扩展了锐龙 AI 嵌入式处理器产品组合,并于近日推出了新款 P100 系列处理器,以更强的算力,为工业与 AI 边缘解决方案提供可靠的支持。
因应需求,再度进化
从AMD的介绍我们得知,和与此前发布的采用相同紧凑型球栅阵列(BGA)封装的 P100 系列处理器一样,新的P100系列同样采用了Zen 5 CPU、XDNA 2 NPU和 RDNA 3.5 GPU的异构集成方案,把所有功能均融于一颗芯片中。但和之前的发布产品不同之处在于,新款处理器可提供最高 2 倍的 CPU 核心数量、最高 8 倍的图形处理单元(GPU)算力,且系统级每秒万亿次运算(TOPS)性能预计提升 36%。
资料显示,此前发布的 P100 系列处理器配备 4-6 颗核心,但新发布的系列涵盖了8到12个CPU核心。与上一代 AMD Ryzen Embedded 8000 APU 相比,其多线程性能提升高达 39%。除此以外,Zen 5核心还提供了隔离能力和充足的性能裕量,可以在单个平台上以确定性的多任务方式整合多个关键工作负载。
来到GPU方面,新发布的P100系列处理器最高拥有8个GPU,能应对更繁重的工作负载。得益于这些配置,使其在处理多4K/8K p120渲染、多叠加人机界面和低延迟视频合成时游刃有余。其集成的AV1解码器和AMD视频引擎,同时带来了高保真、低延迟的流媒体播放和流畅的播放体验。
如上所述,和此前发布的P100系列一样,AMD在新发布的系列处理器上依然集成了NPU。在AMD看来,这个由“iGPU+NPU”组成的端到端AI加速器能够根据需要将工作负载分配给合适的引擎,更好地平衡芯片的功耗和性能。
在这样配置支持下,新推出的P100最高提升 2.1 倍的系统级总TOPS—— 80 TOPS 的系统级算力,与现有 P100 系列相比,新款处理器提供了卓越的 AI 每瓦性能,并可支持近 2 倍数量的虚拟机以及更大规模的大语言模型(例如 Llama 3.2-Vision 11B),从而推动更先进的 AI 与混合型工作负载。
AMD强调,紧密集成的 CPU、GPU 和 NPU 架构能在混合工作负载下实现高效的工作负载分配,并确保可预测的时延;同时,使用熟悉的框架和软件栈有助于在广泛的用例中简化和精简开发与部署。这种集成水平还能在无需额外外部组件的情况下实现先进的计算与图形处理能力,使 OEM 厂商和系统集成商可以更轻松地设计可扩展的平台。
由此可见,除了性能优越的硬件外,软件也是一个产品能否征服客户的另一个关键指标。这也恰好也正是AMD一直深耕的方向。AMD也表示,得益于对 AMD ROCm 开放软件生态系统的支持,公司为嵌入式应用带来了一套业经验证的开源 AI 软件栈。开发人员可以在依赖开源编译器、运行时和库的同时运行标准 AI 框架,并且无需重写代码即可即时访问适用于嵌入式的模型。在编程层面,ROCm 软件采用开源的 HIP (Heterogeneous-computing Interface for Portability),将 GPU 编程从硬件中解耦,消除了软件栈和硬件之间的供应商锁定。
“通过提供跨异构引擎的优化 AI 技术栈,AMD能针对每个引擎优化的软件栈,以实现最佳性能和功耗;同时,该软件栈还支持通用开源框架,可灵活地将工作负载定向到特定引擎;此外,这个软件栈的模型支持涵盖从基础模型到自定义模型,从视觉(CNN)到推理(LLM、VLA)。”AMD补充说。
值得一提的,AMD 还为工业领域的混合关键型应用提供了一个封装式、垂直整合的虚拟参考堆栈。该堆栈基于 Xen 虚拟管理程序构建,可在隔离域中运行 Linux®、 Windows®、Ubuntu® 和 RTOS 环境,从而实现安全性、实时性能与灵活性。最终形成一个可扩展的、开放的架构,为下一代嵌入式系统简化设计并加速开发。
写在最后
据AMD介绍,在这些软硬件支持下,公司新推出的P100系列处理器可支持从视觉到控制到推理的实时 AI、提供先进的图形处理能力,同时还支持工业温度范围(−40℃ 至 105℃)、7×24 小时连续运行以及 10 年产品生命周期,这让其能够在从智慧工厂到工业 PC再到自主机器人和医学成像设备等应用中发挥重要的作用。
AMD进一步指出,新款 x86 嵌入式处理器针对下一代工业和更广泛的边缘 AI 用例进行了优化。这些用例包括:
用于工业 PC 的智能机器视觉:新款处理器能实现将可编程逻辑控制器(PLC)、机器视觉与人机界面(HMI)整合到同一台工业 PC,同时为实时监测与处理优化提供所需的 CPU 性能。集成的 GPU 和 NPU 可加速多路摄像头视觉与丰富的 HMI 仪表板,并支持利用 DeepSORT、RAFT-Stereo、CenterPoint、GDR-Net、PaDiM 和 Llama 3.2-Vision 等模型的低时延异常检测。
用于自主运行的物理 AI:针对移动机器人,该处理器可在 CPU 上管理导航、运动控制与路径规划,而 GPU 则处理多路摄像头数据,实现空间感知、Visual SLAM(视觉 SLAM) 以及视觉-语言-动作(vision-language-action, VLA)模型等高级 AI 工作负载。CPU 与 GPU 之间的统一内存实现了低时延,从而提升了响应速度。NPU 可提供始终在线的低功耗推理,支持基于 YOLOv12 和 MobileSAM 等模型的目标检测与场景理解。
3D 医学成像与临床智能:利用 U-Net、nnU-Net 和 MONAI 等模型,该处理器可在边缘端支持超声、内窥镜、组织分类以及肿瘤检测等 3D 成像。处理器可借助 MedSigLIP 加速从成像到报告的工作流程,并支持通过 Med-PaLM2 实现临床推理与问答能力。医疗领域原始设备制造商(OEM)能在可扩展的长生命周期 x86 嵌入式平台上整合成像、AI 分析与报告功能。
综合来看,8-12核AMD锐龙AI嵌入式 P100 系列并非简单的参数升级,而是针对边缘侧混合工作负载的一次精准提升 。它通过集成 Zen 5 核心的高效逻辑处理、RDNA 3.5 的实时可视化以及 XDNA 2 的低功耗推理,真正解决了物理 AI 在复杂场景下的算力冗余与时延痛点。
随着 2026 年下半年该系列产品的全面量产,嵌入式 AI 市场将迎来一次生产力的集体跃迁。对于那些追求高性能、长生命周期以及开源生态的 OEM 厂商而言,P100 无疑是目前构建下一代智能边缘解决方案的最优解之一。
责任编辑:SemiInsights
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2025 半导体行业观察
Copyright©2023 芯算智能科技(扬州)有限公司
苏ICP备2025200240号-2 皖公网安备 34019202000656号